

Страница 2: Архитектура (1)
В архитектуру "Kepler" NVIDIA внесла многочисленные изменения, которые мы рассмотрим ниже.

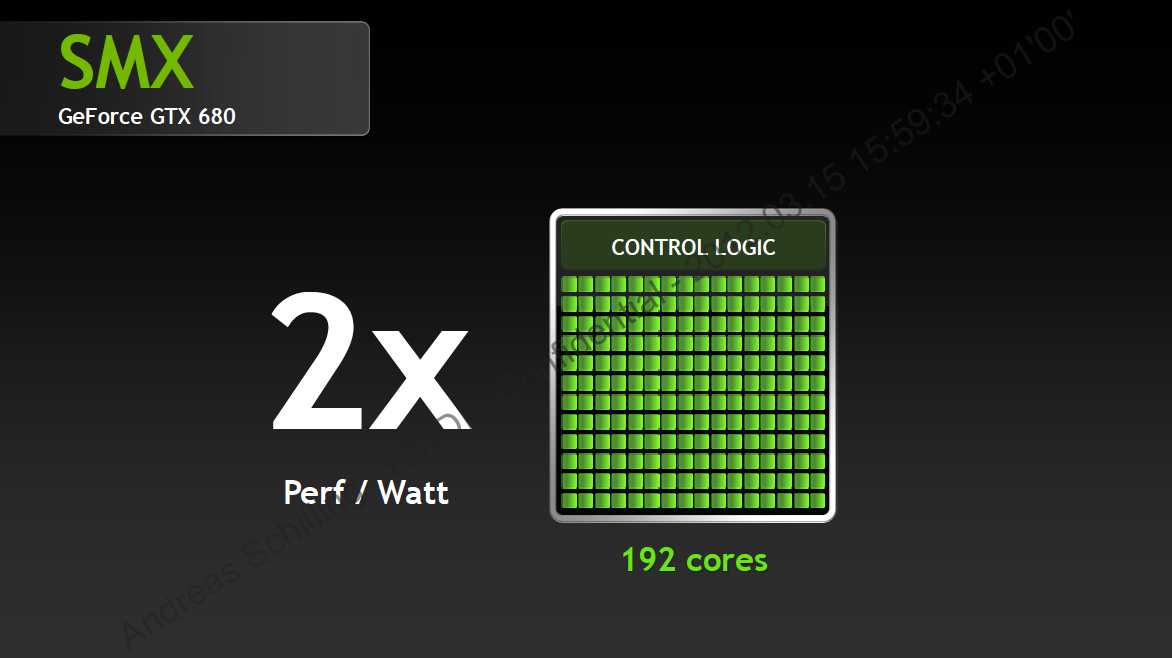
В поколении "Fermi" Nvidia уже использовала термин "потоковые мультипроцессоры/streaming multiprocessors" (SM). Всего в каждом SM присутствует 32 ядра или потоковых процессора. У GeForce GTX 680 или GPU GK104 NVIDIA использует блоки SMX со 192 ядрами. Таким образом, в каждом блоке было не только увеличено количество потоковых процессоров, но изменено соотношение между логикой управления и числом ядер в пользу увеличения числа последних.

GeForce GTX 680 содержит восемь блоков SMX, то есть количество ядер (потоковых процессоров) составляет 8 x 192 = 1536.
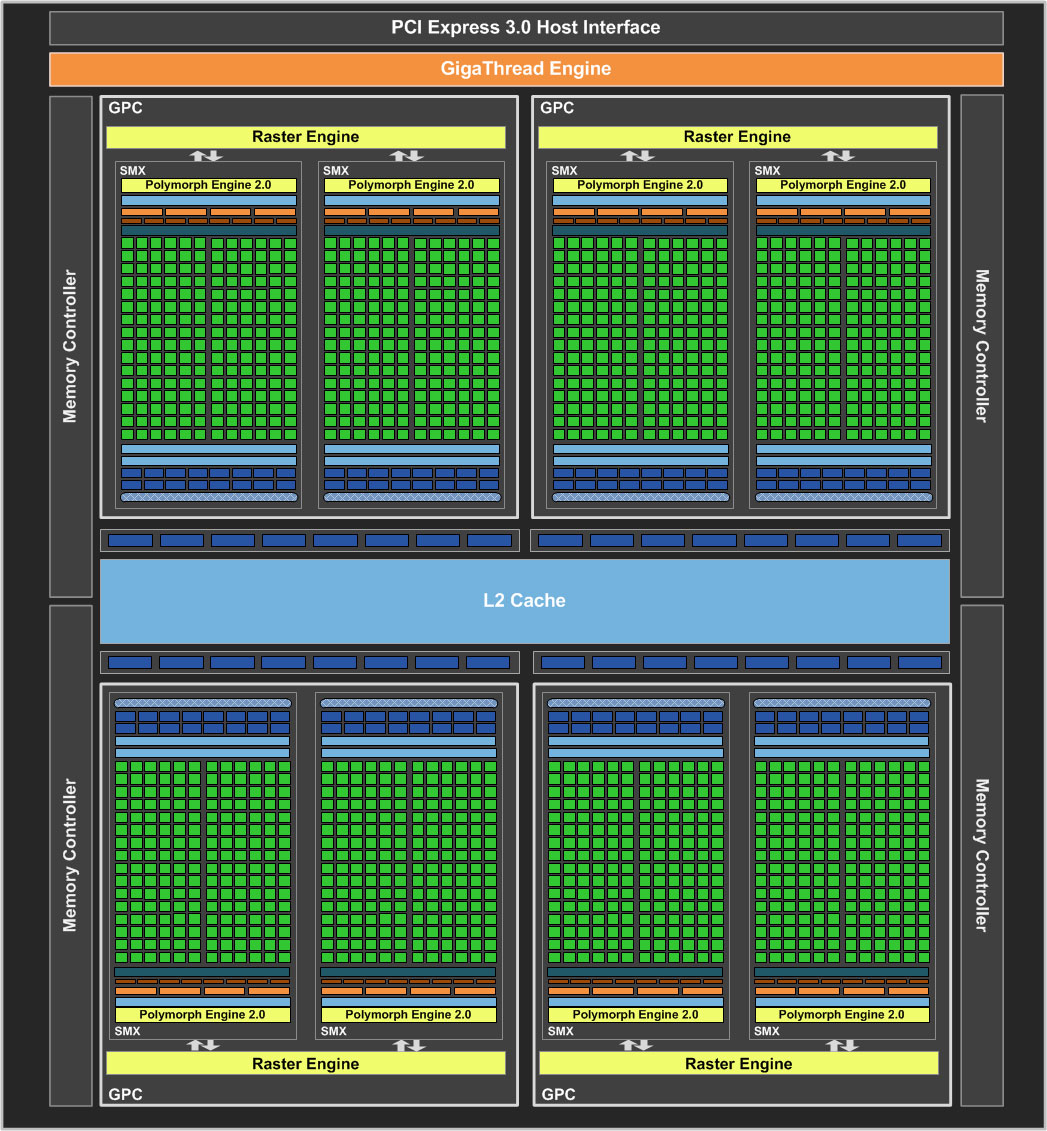
Блочная диаграмма "Kepler" захватывает и внешние области в виде интерфейса PCI Express 3.0 и четырёх контроллеров памяти, которые дают в сумме ширину шины памяти в 256 битов. Расчеты игровой графики выполняются на четырёх кластерах GPC (graphics processing clusters), каждый из которых состоит из пары блоков SMX.
Кэш L2 у архитектуры "Fermi" имел довольно значительный объём 768 кбайт, он позволял кластерам GPC обмениваться данными между собой. Nvidia решила уменьшить размер кэша L2 в архитектуре "Kepler" до 512 кбайт, но при этому увеличила его пропускную способность с 384 байт на такт до 512 байт на такт. Внутри блока SMX по-прежнему используется 64-кбайт кэш L1 или общая память.
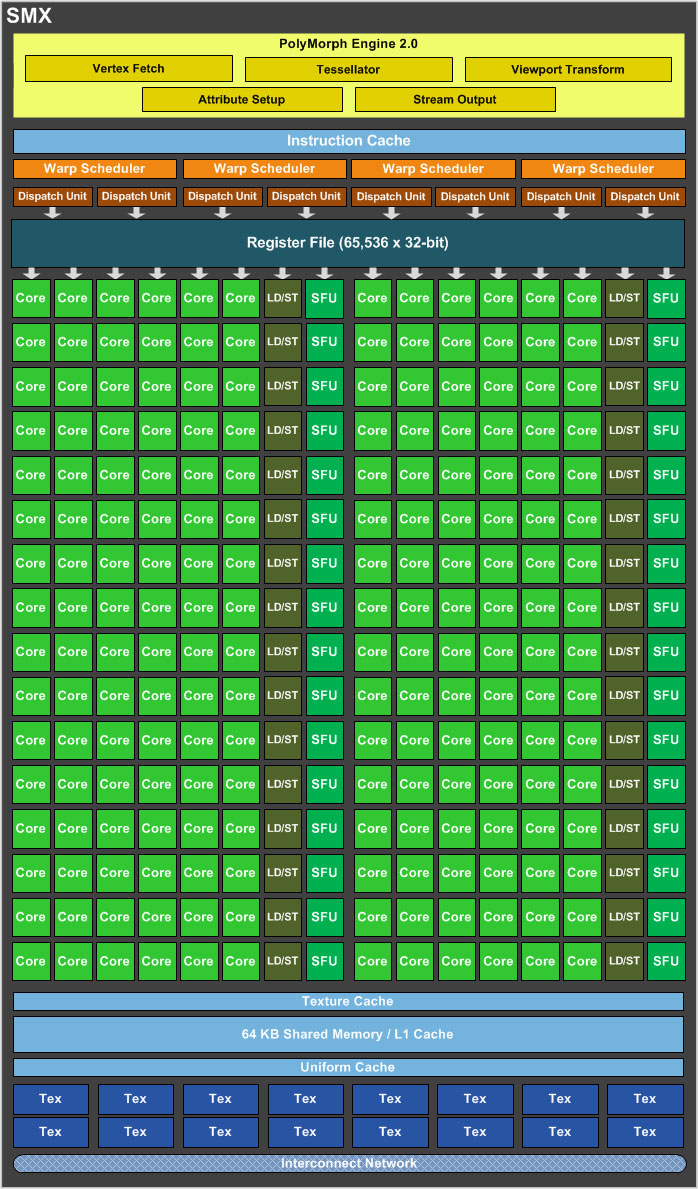
Блок (или кластер) SMX состоит из 192 ядер, 16 текстурных блоков и движка Polymorph 2.0. Каждый кластер SMX оснащен движком PolyMorph 2.0, в результате чего у GK104 мы получаем 8 движков (напомним, что у GeForce GTX 580 их было 16). Движок PolyMorph 2.0 во многом отвечает за функции выборки вершин (Vertex Fetch), тесселяции (Tessellation), настройки атрибутов (Attributes Setup), трансформацию видимой области (Viewport Transform) и потоковый вывод (Stream Output). После прохождения кластера SMX и движка PolyMorph 2.0 результаты вычислений направляются на движок растеризации. На втором шаге тесселятор выполняет вычисления расположения поверхности, и в соответствие с дальностью от зрителя выполняется выбор соответствующего уровня детализации. Скорректированные значения затем возвращаются в кластер SMX, где над ними работают шейдеры домена (Domain Shader) и геометрии (Geometry Shader). Шейдер домена вычисляет финальное положение каждого треугольника, учитывая данные шейдера каркаса (Hull Shader) и тесселяторов. На данном этапе выполняется наложение карт смещения. Затем шейдер геометрии сравнивает вычисленные данные с видимыми объектами на сцене и высылает результаты обратно на движок тесселяции для финального прохода. Затем финальный шаг выполняет движок PolyMorph 2.0 - в виде трансформации видимой области и коррекции перспективы. Затем функция потокового вывода записывает вычисленные данные в память, они могут использоваться для дальнейших расчетов.
Движок Polymorph 2.0 во многом идентичен архитектуре "Fermi", но Nvidia вновь попыталась оптимизировать производительности тесселяции. Собственно, после того, как AMD значительно улучшила свой движок тесселяции в поколении "Southern Islands", у Nvidia не было другого выхода. По информации NVIDIA, GeForce GTX 680 обеспечивает до четырёх раз более высокую производительность тесселяции по сравнению с Radeon HD 7970.

Движок PolyMorph 2.0 в GPU GK104 обеспечивает очень детальными вычисленными значениями четыре параллельных движка растеризации. Сами движки растеризации разделены на три ступени. Первая ступень настройки краев (Edge Setup) отвечает за определение видимых треугольников и отсечение невидимых поверхностей (Back Face Culling). Каждая ступень Edge Setup за такт может вычислять точку, линию или треугольник. Вторая ступень растеризатора (Rasterizer) отвечает за определение значений соответствующего алгоритма сглаживания. Каждый блок растеризтора может вычислять восемь пикселей за так, в результате чего GPU GK104 может вычислять 32 пикселя за такт. Наконец, последняя ступень - блок Z-Cull сравнивает вычисленные пиксели с уже существующими в кадровом буфере. Если вычисленный пиксель геометрически находится позади пикселей в кадровом буфере, то он отбрасывается.
В архитектуре "Kepler" по сравнению с "Fermi" было серьёзно пересмотрено количество конвейеров растровых операций (ROP). В GK104 на каждый блок SMX приходится четыре конвейера ROP, что даёт 32. Для сравнения, у Nvidia GF110 используется 48 конвейеров ROP. В нынешнем GPU восемь конвейеров ROP комбинируются в разделы ROP, которых, если посчитать, будет в GK104 четыре. Каждый конвейер ROP может выдавать 32-битный целочисленный пиксель за такт. Кроме того, возможна обработка пикселей FP16 за два такта или FP32 за четыре такта.
Количество текстурных блоков было удвоено по сравнению с предшествующим GPU. В каждом блоке SMX используется 16 текстурных блоков, в результате чего у GK104 или GeForce GTX 680 мы получаем 128 блоков.
Интерфейс памяти претерпел значительные изменения. Каждый раздел ROP подключен по 64-битному интерфейсу памяти. В случае четырех разделов ROP мы получаем 256-битный интерфейс памяти. У GF110 имелось шесть разделов ROP, которые вместе составляли 384-битный интерфейс памяти.

В случае "Kepler" Nvidia изменила соотношение между вычислительными ядрами и логикой управления, а также и частоту работы ядер. Напомним, что графический процессор "Fermi" производился по технологии 40 нм и содержал 3 млрд. транзисторов. Потоковые процессоры работали на удвоенной тактовой частоте по сравнению с остальной частью GPU, то есть выполняли две вычислительные операции на такт GPU. Только через подобный подход "Hotclocks" Nvidia смогла обеспечить необходимую вычислительную производительность.
В случае "Kepler" NVIDIA опиралась на новый техпроцесс, что несколько решило проблему с большой площадью кристалла (техпроцесс уменьшился, количество транзисторов возросло незначительно).