
За последние десять лет графические процессоры все чаще используются не только для 3D-рендеринга, но и для вычислений и искусственного интеллекта. В нашу жизнь вошла трассировка лучей, а искусственный интеллект способен уже не только на отдельные эффекты, но и на реконструкцию целых кадров. В этом FAQ мы хотим ответить на вопросы о том, как работают графические процессоры и видеокарты.
Видеокарта класса GeForce RTX 4090 сегодня достигает вычислительной мощности, которая еще несколько лет назад была уделом целых мэйнфреймов. Но мониторы 4K и новейшие графические эффекты представляет собой огромный вызов с точки зрения вычислительной производительности. Как всегда, существует гонка между аппаратными требованиями игр и производительностью, предлагаемой видеокартами. Однако в случае с такими тяжелыми вычислениями, как трассировка пути, мы уже достигли уровня, который вряд ли возможен без поддержки ИИ. По крайней мере, с точки зрения производительности современных видеокарт.

Но чем видеокарты отличаются друг от друга? В чем смысл таких терминов, как ядра SM, RT, вычислительные блоки Tensor? Как работает трассировка лучей в реальном времени и DLSS с сетью глубокого обучения? В нашей статье мы постараемся ответить на эти и другие вопросы.
Мы рассмотрим видеокарту внутри и снаружи, поговорим о функциях и интерфейсах, системе охлаждения и других интересных аспектах.
Подписывайтесь на группу Hardwareluxx ВКонтакте и на наш канал в Telegram (@hardwareluxxrussia).
Внешняя структура и дизайн
Видеокарты выпускаются в разных форматах. Дискретные видеокарты обычно приобретаются как карты расширения PCI Express, но видеокарты могут интегрироваться в CPU. В ноутбуках они также могут припаиваться на материнскую плату или устанавливаться в виде модулей MXM, которые намного компактнее дискретных решений PCIe и лучше подходят для тесного пространства внутри ноутбука.
С линейкой GeForce RTX 40 произошли новые изменения. Разделение между мобильными и настольными GPU теперь заключается не столько в разных уровнях конфигурации, сколько в уровне энергопотребления Power Limit. Система охлаждения ноутбука стала решающим фактором, влияющим на производительность GPU.
Но за последние годы произошли и некоторые изменения в сегменте настольных видеокарт, которые повлияли на дизайн системы охлаждения.

Форм-фактор видеокарты зависит от сферы использования, но бывают отличия и внутри семейств. В прошлом видеокарта вместе с кулером редко занимала по ширине больше двух слотов, но сегодня данное ограничение уже не выполняется. Причина кроется и в спецификациях максимальной потребляемой мощности. Для серии GeForce RTX 40 изначально планировался уровень до 600 Вт, хотя в итоге NVIDIA ограничилась 450 Вт. Соответственно, требования к охлаждению возросли. В том же сегменте high-end толщина видеокарты в три слота и более уже является стандартом. Некоторые модели занимают даже четыре слота.
Конечно, на материнской плате должно быть достаточно места. Многие производители предусматривают соответствующее расстояние между первым и остальными слотами PCI Express. Однако увеличивается потребность в пространстве не только на материнской плате, но и, прежде всего, в корпусе. При покупке high-end видеокарты важно проверить, уместится ли она в корпусе по длине.
Низкопрофильные видеокарты встречаются довольно редко, они превратились в специализированный продукт. Производители выпускают низкопрофильные однослотовые видеокарты разве что для некоторых сценариев использования - например, для серверного сегмента, когда имеются ограничения по занимаемому пространству. Что касается толщины, ее у видеокарты можно уменьшить с двух-трех слотов до одного, если установить водоблок СВО. Поэтому даже high-end видеокарты можно превратить в однослотовые, разве что потребуется соответствующая слотовая заглушка.

Как и в случае толщины, по длине видеокарты тоже наблюдается существенный разброс. Обычно производители придерживаются спецификаций ATX, но есть модели существенно длиннее. Стандарт ATX оговаривает длину до 305 мм. Если видеокарта будет длиннее, то могут возникнуть проблемы с установкой в корпус. Например, может мешаться стойка накопителей. Видеокарты современного поколения достигают длины 300 мм даже в среднем ценовом сегменте. Некоторые high-end модели еще длиннее, поэтому перед покупкой видеокарты и/или корпуса следует убедиться, что она не будет конфликтовать с той же стойкой накопителей.
Некоторые производители выпускают очень компактные видеокарты. Например, предназначенные для систем Mini-ITX, где доступное пространство очень сильно ограничено. Здесь приходится решать еще и вопрос охлаждения, поскольку при небольшом объеме весьма сложно вывести 200 или 300 Вт тепла.
Производительность видеокарты косвенно сказывается на длине. Бюджетные модели оснащаются меньшим объемом видеопамяти и менее мощной системой питания, их можно сделать более компактными.
Охлаждение
Радиальный вентилятор (турбина)
На видеокартах используют разные системы охлаждения, которые связаны с форм-фактором и дизайном. Между тем многие производители перешли на осевые вентиляторы, которые оказались более эффективными. Радиальные вентиляторы все еще встречаются, особенно когда требуется направленный воздушный поток через радиатор видеокарты в сторону слотовой заглушки. В частности, такой подход используют видеокарты для рабочих станций и серверов, поскольку уровень шума здесь роли не играет, однако необходимо гарантировать определенную производительность охлаждения.
Осевой вентилятор
В случае систем охлаждения на основе осевых вентиляторов последние располагаются над радиатором и продувают воздух напрямую на радиатор. Впрочем, конструкция вентиляторов за последние годы претерпела немало инноваций, поэтому строгого разделения между радиальным и осевым вентиляторами уже нет. Кроме того, особое внимание уделяется прохождению воздушного потока через радиаторы, чтобы воздух выбрасывался через нужные отверстия.
В отличие от кулера с радиальным вентилятором, здесь большая часть горячего воздуха остается внутри корпуса, а не выбрасывается наружу через слотовую заглушку. Поэтому в корпусе необходимо обеспечить достаточную вентиляцию.

Видеокарты линейки GeForce RTX 40 от NVIDIA выделяют до 450 Вт тепла, поэтому компании пришлось разработать новую концепцию охлаждения. NVIDIA взяла за основу воздушный поток внутри корпуса, когда свежий воздух поступает спереди, а горячий выбрасывается сзади или сверху.
Видеокарта с радиальным вентилятором-турбиной хорошо вписывается в подобный дизайн, поскольку забирает воздух внутри корпуса, после чего выбрасывает его сзади через слотовую заглушку. А для кулера с осевыми вентиляторами данная концепция уже не работает. Большая часть воздуха остается внутри корпуса, крупные печатные платы сплошные панели ухудшают продуваемость. Благодаря крупным кулерам с несколькими вентиляторами теплый воздух более-менее хорошо распределяется внутри корпуса.

Для своих старших видеокарт Founders Edition NVIDIA разработала новый дизайн, в котором основной вентилятор продувает часть воздуха сквозь видеокарту в сторону кулера CPU. А второй вентилятор в передней части направляет часть воздуха наружу через слотовую заглушку.
Конечно, NVIDIA пришлось укоротить PCB и изменить ее конструкцию, чтобы основной вентилятор продувал часть воздуха через видеокарту. В итоге у большинства видеокарт используется короткая PCB, а задняя часть видеокарты целиком выделена под охлаждение.
Водяное охлаждение

Чтобы гарантировать наилучшее охлаждение, многие производители оснащают видеокарту водоблоком. Из-за более быстрого и эффективного отведения тепла, СВО хорошо подходит для разгона видеокарт. А также для охлаждения "прожорливых" high-end моделей. Используются как медные водоблоки с полным покрытием, которые можно интегрировать в контур существующей СВО, так и решения с замкнутым контуром или "все в одном", которые содержат помпу, резервуар, теплообменник и трубки.
Интерфейс PCI Express
Сегодня все видеокарты, будь то для настольных ПК, ноутбуков или внешние модели Thunderbolt 4, подключаются к системе по интерфейсу PCI Express. Между тем некоторые разработчики GPU представили собственные интерфейсы. В случае NVIDIA, например, для подключения вычислительных ускорителей в дата-центрах используется NVLink с двунаправленной пропускной способностью до 900 Гбайт/с.
На сегодняшний день современным является стандарт PCI Express 5.0 с пропускной способностью 3,938 Гбайт/с на линию. Хотя две потребительские платформы AMD и Intel уже поддерживают PCI-Express 5.0, это еще не означает, что так будет и с видеокартами. AMD, NVIDIA и Intel пока не перешли на PCI Express 5.0 со своими видеокартами и предлагают поддержку только PCI-Express 4.0.
Как правило, графические процессоры в настольных видеокартах подключаются по 16 линиям, что дает 31,508 ГБ/с при использовании PCI Express 4.0. Для видеокарт в ноутбуках, в зависимости от используемого процессора и GPU, может быть доступно только восемь или даже четыре линии, что снижает пропускную способность в два или четыре раза. С другой стороны, подключение по восьми линиям обычно не является ограничением благодаря использованию вполне быстрого стандарта PCI Express 4.0. Определенную разницу можно измерить, но заметит ли ее игрок – уже другой вопрос. Восемь линий PCIe 4.0 обеспечивают ту же скорость передачи данных, что и 16 линий PCIe 3.0. С переходом на PCI Express 5.0 этот факт должен стать еще менее значимым.

В любом случае, классические настольные видеокарты подключаются по 16 линиям с пропускной способностью 31,5 ГБ/с. Более быстрое подключение видеокарт к системе может стать более важным при использовании Direct Storage. Однако в настоящее время технология Direct Storage ограничена не связью между GPU и остальной системой, а API как таковым. Это становится ясно при сравнении NVMe SSD с PCIe 3.0 и 4.0 или 5.0 в тестах Direct Storage. Измеряемая разница есть только по времени загрузки сохранений или уровней, но игрок и этого не заметит.
Поддержка PCI Express 5.0 уже появилась на платформах, но еще не на видеокартах. В серверном сегменте ситуация иная. Здесь пропускная способность играет гораздо более важную роль.
Интерфейс PCI Express является центральным элементом обмена данных между видеокартой и остальной системой. За прошедшие годы AMD и NVIDIA уделили ему пристальное внимание, добавив поддержку функции Resizable BAR (rBAR). rBAR упрощает доступ к видеопамяти, увеличивая производительность.
Поддержка Resizable BAR присутствует у систем с процессорами AMD, начиная с Zen 3 (линейка Ryzen 5000), а также Intel Core 10 и новее. Что касается чипсетов, то в случае AMD необходимы материнские платы на чипсетах 400 (которые поддерживают процессоры Ryzen 5000) или 500. Производители материнских плат либо активируют опцию Resizable BAR в UEFI по умолчанию, либо размещают ее на видном месте.
Для использования Resizable BAR технология должна быть включена в UEFI. Соответствующие опции могут называться "Above 4G memory/Crypto Currency mining" или "Re-Size BAR Support", они обычно располагаются в разделе настроек PCI Express в UEFI. Проверку активной опции rBAR можно выполнить в Панели управления NVIDIA в пункте "Resizable BAR". Конечно, можно воспользоваться и такими утилитами, как GPU-Z.
Видеовыходы
После того, как GPU выполнит рендеринг изображения, его необходимо вывести на монитор. У всех видеокарт для этой цели есть соответствующие видеовыходы. Могут встречаться HDMI или DisplayPort, старые стандарты VGA и DVI уже практически не используются. Все же медленный цифровой стандарт DVI или аналоговый VGA уже не соответствуют современным требованиям по качеству передачи. В зависимости от разрешения и частоты обновления, требуется пропускная способность порядка нескольких гигабит в секунду.
HDMI
HDMI (High Definition Multimedia Interface) не только обеспечивает высокие разрешения, но и передачу сигнала аудио от видеокарты на монитор. Через HDMI возможно даже сетевое подключение. Максимальная пропускная способность HDMI несколько раз увеличивалась со сменой поколений. Что позволило не только увеличить разрешение, но и передавать больше различных форматов аудио, а также большую глубину цвета.
У спецификации 1.0 поддерживается скорость передачи данных составляет 3,96 Гбит/с, при этом обеспечивается электрическая совместимость с DVI. Интерфейс позволяет передавать картинку в разрешении 1.920 x 1.080 пикселей с частотой обновления 60 Гц, одновременно поддерживается передача восьми каналов аудио. В случае HDMI 1.3 повышение пропускной способности до 8,16 Гбит/с позволило увеличить разрешение до 2.560 x 1.440 пикселей на 60 Гц. HDMI 1.4 увеличил возможное разрешение до 3.840 x 2.160 пикселей, но только на 24 Гц.
В стандарте HDMI 2.0 данное «узкое место» было устранено, теперь поддерживается разрешение UHD на 60 Гц. Пропускная способность современного стандарта HDMI составляет 14,4 Гбит/с. Что касается аудио, поддерживаются 32 канала с частотой дискретизации 1.536 кГц. В HDMI 2.0a была впервые добавлена поддержка HDR (High Dynamic Range - высокий динамический диапазон). Все современные видеокарты NVIDIA поддерживают стандарт не ниже HDMI 2.0b, обеспечивающий динамическую синхронизацию нескольких потоков аудио и видео.
Между тем появился стандарт HDMI 2.1a. Пропускная способность увеличена до 48 Гбит/с, что обеспечивает разрешения до 7.680 x 4.320 пикселей на 120 Гц. Однако для этого используется сжатие потока данных Display Stream Compression, оно выполняется с потерями, но существенно влияния на качества картинки нет.

DisplayPort
DisplayPort - стандарт, разработанный VESA (Video Electronics Standards Association), который является альтернативой HDMI. Как и PCI Express, стандарт DisplayPort опирается на линии. С первой версии и до нынешней DisplayPort 2.0 используется четыре линии, которые становились быстрее от версии к версии, поэтому и пропускная способность увеличивалась.
Стандарты DisplayPort 1.0 и 1.1a обеспечивают пропускную способность 10,8 Гбит/с, то есть DisplayPort был с самого начала был быстрее HDMI. Поэтому изначально была возможна передача сигнала в разрешении UHD. DisplayPort 1.2 стал важным шагом, поскольку он добавил функцию Adaptive Sync для синхронизации частоты кадров видеокарты и монитора. То есть дисплей теперь не обновляет картинку с собственной частотой 24, 30 или 60 Гц, а может синхронизировать частоту обновления с видеокартой - например, 40 кадров в секунду. NVIDIA по нескольким причинам выбрала проприетарную технологию под названием G-Sync, о которой мы поговорим чуть ниже.
У современного поколения видеокарт GeForce RTX NVIDIA поддерживает технологию DisplayPort 1.4a. Пропускная способность 32,4 Гбит/с несколько ниже HDMI 2.1a. Долгое время DisplayPort технически превосходил стандарты HDMI, но благодаря быстрой разработке HDMI смог на этом этапе догнать конкурента. В итоге выбор между интерфейсами подключения HDMI или DisplayPort зависит от характеристик монитора, частоты обновления и максимального разрешения.
Видеокарты с современными графическими процессорами AMD и Intel уже используют DisplayPort 2.1. Режимы передачи UHBR 10, UHBR, UHBR 13.5 и UHBR 20 позволили увеличить пропускную способность до 20 Гбит/с на линию. Суммарная скорость передачи данных составляет 80 Гбит/с, что значительно выше, чем у HDMI 2.1. Кроме того, уже есть приблизительные планы на следующую версию DisplayPort. Она должна удвоить скорость передачи данных и, следовательно, соответствовать будущим потребностям. Однако более подробных спецификаций пока нет. В настоящее время на видеокартах NVIDIA используются стандарты HDMI 2.1 и DisplayPort 1.4.
Дополнительное питание
Современные high-end видеокарты не обходятся без дополнительного питания. Конечно, слот PCI Express способе обеспечивать определенную мощность. Но лишь 75 Вт по линиям 12, 5 и 3,3 В. Производительным видеокартам требуется намного больше 75 Вт, поэтому и требуется дополнительное питание. Как правило, штекеры питания располагаются в задней части видеокарты.
Существуют два распространенных штекера дополнительного питания спецификации PCI Express с шестью и восемью контактами. Соответственно, 6-контактный вариант обеспечивает подачу мощности до 75 Вт, в случае 8-контактной версии речь идет о 150 Вт. Впрочем, указанные 75 и 150 Вт являются не физическими ограничениями штекеров, а расчетными спецификациями производителей блоков питания.

С видеокартами GeForce RTX 3090 Ti, а затем и во всех картах серии GeForce RTX 40, NVIDIA перешла на разъем питания 12VHPW. Он позволяет передавать до 600 Вт мощности и избавляет от необходимости использовать до трех разъемов и кабелей, как это было бы со старыми 8-контактными штекерами. В спецификации ATX 3.1 есть небольшие изменения по стандарту 12V-2×6, но разъем совместим с 12VHPWR.
Поэтому разъемы PCI Express с шестью и восемью контактами рано или поздно исчезнут. Некоторые партнеры NVIDIA все еще используют их в видеокартах среднего и младшего класса, но в следующем поколении с ними точно можно будет попрощаться. AMD и Intel, скорее всего, последуют примеру NVIDIA.
GDDR6X как стандарт де факто
Помимо GPU, важным компонентом видеокарты остается память, поскольку она должна как можно быстрее обеспечивать графический процессор данными. Данные на видеокарту поступают через интерфейс PCI Express, они загружаются в видеопамять, после чего к ним может обращаться GPU с пропускной способностью почти 1 Тбайт/с. С годами технологии памяти совершенствовались.
GDDR (Graphics Double Data Rate) остается важным стандартом памяти современных видеокарт помимо High Bandwidth Memory (HBM). Как и в случае оперативной памяти DDR на материнских платах, GDDR тоже прошла через несколько поколений. В случае памяти DDR (и GDDR) передача данных производится на подъеме и спаде тактового сигнала. Со сменой поколений пропускная способность памяти GDDR существенно увеличилась. Вместе с тем энергопотребление продолжало снижаться. Память GDDR по 256-битному интерфейсу дает пропускную способность 25,6 Гбайт/с. У GDDR6X она достигает 936 Гбайт/с, планируются и более быстрые варианты. Тактовые частоты с поколениями увеличились со 166 МГц до нынешних 2.000 МГц и выше.
В текущих видеокартах серии GeForce RTX 40 NVIDIA использует память GDDR6(X), которая теперь выпускается всеми основными производителями памяти. Память GDDR6X работает примерно на тех же частотах, что и GDDR6, напряжения тоже сравнимы. Но отличия имеются, к ним мы вернемся чуть ниже.

За последние годы было несколько попыток перейти на память HBM на рынке видеокарт. Однако высокая себестоимость памяти HBM и соответствующего интерфейса привели к тому, что сегодня почти все видеокарты оснащаются GDDR6X. На серверном сегменте все иначе. NVIDIA предлагает архитектуру Hopper в сочетании с памятью HBM2E, а именно H100 Tensor GPU. HBM2E теперь достигает скорости передачи данных до 4 ТБ/с и выше, в то время как GDDR6X на данный момент находится на пределе – около 1 ТБ/с.
Пропускная способность памяти - спецификация техническая. Она дополняется различными алгоритмами сжатия данных в памяти. Что позволяет как сэкономить доступное пространство в памяти, так и ускорить передачу данных. Например, уже несколько поколений GPU NVIDIA используют цветовую дельта-компрессию. NVIDIA уже внедрила шестое поколение подобной компрессии.
Важно понимать, что сжатие выполняется без потерь. Так что никакие данные не искажаются, и разработчикам не приходится адаптировать свои продукты каким-либо образом.
NVIDIA использует для сжатия памяти цветовую дельта-компрессию (Delta Color Compression). Она основана на хранении полной цветовой информации только о базовом пикселе, для остальных пикселей сохраняется разница с базовым (дельта). Для этой цели используется матрица 8x8 пикселей. Поскольку близко расположенные пиксели обычно мало отличаются по цвету, хранение для них разницы оказывается по объёму информации выгоднее, чем полного значения цвета. Поэтому в случае дельта-компрессии информация о пикселях занимает меньше места в памяти, также достигается экономия пропускной способности памяти. В качестве примера работы технологии можно привести полностью черный и белый блоки, которые будут храниться в памяти как {1.0, 0.0, 0.0, 0.0} или {0.0, 1.0, 1.0, 1.0}. Здесь можно сэкономить ресурсы, сохраняя только 0.0 или 1.0 в качестве значения.
NVIDIA улучшила процедуру определения сжимаемого контента. Ранее известное соотношение 2:1 теперь может использоваться чаще, то есть применяться к большему массиву данных. Появились и соотношения сжатия 4:1 и 8:1.
Сжатие цветовой информации позволяет увеличить эффективную пропускную способность памяти, поскольку физически ей приходится передавать меньше информации. Что повышает эффективность работы интерфейса памяти.
С контроллером GDDR6(X) NVIDIA продолжила использовать технологию определения и исправления ошибок Error Detection and Replay (EDR). Память GDDR6X работает на эффективной частоте порядка 1.200 МГц. Память становится все сложнее, частоты увеличиваются, поэтому ошибки неизбежны. По этой причине с памятью DDR5 была добавлена ECC на кристалле. И подобная встроенная поддержка ECC вполне сравнима с EDR.
Через Error Detection and Replay определяются ошибки (Error Detection), после чего данные передаются повторно, пока ошибок не будет (Replay). Теперь ошибки передачи определяются на уровне контроллера памяти и не приводят к появлению артефактов. Для проверки целостности данных применяется алгоритм Cyclic Redundancy Check (CRC). Если данные будут повреждены при передаче, то контрольная сумма CRC не совпадет.
Без CRC или Error Detection and Replay на высоких частотах повышается риск возникновения ошибок и появления артефактов. Также есть риск краха драйвера или системы.
Благодаря Error Detection and Replay ошибки получается выявлять и исправлять. Но при дальнейшем разгоне можно выйти на уровень, когда пропускную способность далее увеличить уже не получается. Но до этого уровня «вылетов» не происходит, можно надеяться на безошибочную работу. Таким образом, EDR не только защищает целостность данных при обычной работе видеокарты, но и помогает разогнать память до предела возможностей.
Подсистема питания
Подсистема питания играет важную роль на современных видеокартах. NVIDIA как раз недавно существенно улучшила систему питания на эталонных дизайнах. В линейке GeForce RTX 40 система питания очень мощная и качественная, что видно по моделям Founders Editions и эталонным дизайнам, которые используются партнерами.
Подсистема питания GPU, памяти и других компонентов важна для эффективной и стабильной работы видеокарты. Все же речь идет о питании до 76,3 млрд. транзисторов в случае 5-нм техпроцесса, с несколькими уровнями напряжения, которые должны быть точно отрегулированы. Кроме того, система питания должна гибко адаптироваться в зависимости от нагрузки. Наконец, потери на подсистеме питания должны быть минимальны, то есть она не должна становиться существенным потребителем энергии.
В составе подсистемы питания важную роль играют модули стабилизации напряжения VRM (Voltage Regulator Modules). Они гарантируют, что напряжение 12 В, которое поступает от блока питания ПК, будет преобразовано в напряжение около 1 В, которое необходимо для питания GPU и памяти.
Многие производители подчеркивают большое число фаз подсистемы питания. Однако подход «больше – лучше» здесь работает не всегда. Как правило, чем выше тепловой пакет, то есть энергопотребление видеокарты, тем больше фаз должна содержать подсистема питания.

Правило следующее: чем больше фаз подсистемы питания установлено на видеокарту, тем лучше она справляется с подачей питания при высоких токах. Вместе с тем если фаз больше, чем требуется, то эффективность снижается. Все же большое число фаз приводят к потерям при стабилизации. Поэтому NVIDIA начиная с линейки GeForce RTX 20 разработала систему, которая может динамически включать и выключать фазы - в зависимости от того, сколько именно питания требуется для видеокарты. В результате подсистема питания всегда обеспечивает идеальный баланс. У GeForce RTX 4090 подсистема питания 20-фазная, при этом она может динамически включать/выключать фазы. У видеокарты GeForce RTX 4080 число фаз составляет 18, у младших моделей с меньшим энергопотреблением число фаз пропорционально уменьшается.
Новое подключение питания 12VHPWR устраняет необходимость балансировки между двумя или более разъемами питания PCI Express. Однако видеокарты, которые по-прежнему используют более двух старых разъемов питания, должны учитывать балансировку в дизайне системы питания.
Корпусировка GPU
Конечно, самый важный компонент видеокарты - это GPU. Но в данном случае подразумевается не просто кристалл на PCB (Printed Circuit Board), но корпусировка GPU. Упаковка GPU состоит из подложки, обычно тоже PCB, к которой кристалл крепится через массив шариков BGA (Ball Grid Array). Впрочем, некоторые GPU напрямую припаиваются к PCB видеокарты через BGA и без подложки. Опять же, здесь все зависит от корпусировки GPU.
Если посмотреть на типичную корпусировку GPU, то графический процессор будет расположен по центру, его окружают различные компоненты SMD, по большей части резисторы. Упаковка GPU припаивается к PCB видеокарты через BGA. В показанном примере видеопамять GDDR6(X) расположена вне корпусировки GPU, на видеокарте.
Однако NVIDIA также выпускает графический процессор H100, в котором видеопамять расположена в непосредственной близости в виде HBM2E. GPU и HBM расположены на единой подложке Interposer. Причем подложка Interposer тоже имеет свою структуру с вертикальными и горизонтальными соединениями, которые обеспечивают связь между GPU и HBM.

Преимущество HBM заключается в очень широком интерфейсе памяти, который обеспечивает высокий уровень пропускной способности. Но данный интерфейс возможен только через подложку Interposer, поскольку на чип памяти приходится 1.024 дорожек. С двумя или четырьмя чипами памяти количество дорожек пропорционально увеличивается и превышает 6.000. Производство подложки Interposer - процесс довольно трудоемкий и затратный, он обходится дороже, чем просто установка корпусировки GPU через BGA на PCB видеокарты. Кроме того, производителю видеокарты уже недостаточно просто купить GPU и смонтировать его на видеокарту; в цепочке производства задействуются дополнительные компании, которые устанавливают GPU и HBM на подложку.
Собственно, в этом кроется одна из причин (помимо доступности и цен самой HBM), почему память HBM сегодня устанавливается лишь на ускорители для ЦОД, но не на видеокарты GeForce RTX.
Что скрывается за потоковым процессором, блоком шейдеров или ядром CUDA?
Ядро CUDA, потоковый процессор, блок шейдеров – все это синонимы вычислительного блока GPU, который выполняет расчет данных. NVIDIA по традиции называет их ядрами CUDA, где CUDA расшифровывается как Compute Unified Device Architecture. Ядра CUDA отличаются от ядер процессора, они намного менее сложные и имеют высокую степень специализации под обрабатываемые данные. GPU сегодня умеют намного больше, чем выполнять рендеринг графики через конвейер, поэтому унификация под названиями потоковый процессор или унифицированный блок шейдеров вполне обоснована.
Потоковый процессор обрабатывает непрерывный поток данных, которых насчитываются многие сотни, причем они выполняются параллельно на множестве потоковых процессоров. Современные GPU оснащаются несколькими тысячами потоковых процессоров, они отлично подходят для задач с высокой степенью параллельности. Это и рендеринг графики, и научные расчеты. Что, кстати, позволило GPU закрепиться в серверном сегменте в качестве вычислительных ускорителей.

Впрочем, потоковые процессоры - довольно общий термин, на практике у современных GPU все сложнее. GPU могут выполнять как вычисления с плавающей запятой (FP), так и целочисленные (INT) с различной точностью. Для графики важнее всего вычисления FP32 и INT32 с 32-битной точностью. В случае научных расчетов все более важными являются расчеты с более высокой точностью, а именно FP64. Поэтому в GPU появились выделенные вычислительные блоки для типа данных FP64. Впрочем, далеко не для всех расчетов нужна точность с 32 и 64 битами. Были разработаны способы выполнения менее точных вычислений на блоках INT32, например, одновременное выполнение операций над двумя 16-битными целыми числами.
Еще одним шагом дальше можно назвать интеграцию ядер Tensor в архитектуре NVIDIA Ampere, которые способны эффективно выполнять менее сложные вычисления INT8 и INT4, но об этом мы поговорим чуть позже.

Ниже на примере архитектуры Ada Lovelace мы рассмотрим структуру вычислительных блоков, ведь в GPU не просто несколько тысяч шейдерных блоков, они организованы определенным образом.
В составе GPU AD102 имеются 12 кластеров Graphics Processing Clusters (GPC) с 12 потоковыми мультипроцессорами Streaming Multiprocessors (SM) каждый. Но на видеокартах GeForce RTX 4090 и GeForce RTX 4080 активны не все SM. AD102 GPU теоретически содержит 18.432 блока FP32 (12 GPC x 12 SM x 128 блоков FP32). Но у GeForce RTX 4090 16 SM отключены, поэтому видеокарта предлагает «всего» 16.384 блока FP32. Такой подход повышает выход годных чипов NVIDIA, поскольку наличие нескольких дефектных SM не приводит к отбраковке кристалла.
В GeForce RTX 4080 уже используется более компактный GPU AD103, который имеет в общей сложности 8 SM, 6 из которых активны, что дает 9.728 потоковых процессоров. Для GeForce RTX 4070 Ti и GeForce RTX 4070 используется GPU AD104. Ниже NVIDIA расположила GPU AD106 и AD107, которые устанавливаются в видеокарты GeForce RTX 4060 (Ti). О том, что это GPU проектировались для ноутбуков, говорит и тот факт, что интерфейс PCI Express сокращен до восьми линий.
Одновременное выполнение операций с целыми числами и числами с плавающей запятой
Как мы уже упоминали, вычислительные блоки FP32 могут работать в режиме 2x FP16, то же самое касается INT16. Чтобы увеличить вычислительную производительность и сделать ее более гибкой, в архитектуре NVIDIA Turing появилась возможность одновременного расчета чисел с плавающей запятой и целых чисел. Конечно, подобная возможность сохранилась и в архитектурах Ampere и Ada Lovelace. NVIDIA проанализировала данные вычисления в конвейере рендеринга в десятках игр, обнаружив, что на каждые 100 расчетов FP выполняется примерно треть вычислений INT. Впрочем, значение среднее, на практике оно меняется от 20% до 50%. Конечно, если вычисления FP и INT будут выполняться одновременно, то конвейеру придется иногда "подтормаживать" в случае взаимных связей.
Соотношение 1/3 INT32 и 2/3 FP32 отражено в структуре Streaming Multiprocessor (SM), составляющем элементе архитектуры Ada Lovelace. NVIDIA удвоила число вычислительных блоков FP32 на каждый SM. Вместо 64 блоков FP32 на SM, их теперь насчитывается 128. Плюс 64 блока INT32. Теперь на квадрант SM насчитывается два пути данных, некоторые могут работать параллельно. Один из путей данных содержит 16 блоков FP32, то есть может выполнять 16 вычислений FP32 за такт. Второй путь данных содержит по 16 блоков FP32 и INT32. Каждый из квадрантов SM может выполнять либо 32 операции FP32, либо по 16 операций FP32 и INT32 за такт. Если же брать SM целиком, то возможно выполнение 128 операций FP32 или по 64 операции FP32 и INT32 за такт.
Параллельное выполнение продолжается и на других блоках. Например, ядра RT и Tensor могут работать параллельно в конвейере рендеринга, что снижает время, требующееся на рендеринг кадра.
Под термином «потоковые процессоры» сегодня подразумевают количество вычислительных блоков GPU, хотя следует помнить, что сложность вычислений бывает разной. Поэтому термин используется гибко, но обычно все равно описывает вычислительные блоки.
Текстурные блоки
Потоковые процессоры выполняют так называемые шейдеры - небольшие программы. Вершинные шейдеры используются для геометрических вычислений и динамического изменения объектов. Геометрические шейдеры позволяют рассчитать финальную геометрию и структуру объекта из точек, линий и треугольников. Шейдеры тесселяции обеспечивают дальнейшее разделение примитивов (тех же треугольников).
Текстурные блоки Texture Mapping Units (TMU) отвечают за то, чтобы все поверхности были покрыты соответствующими текстурами. TMU - выделенные вычислительные блоки GPU. В случае архитектуры Ada Lovelace, один текстурный блок дополняет 16 потоковых процессоров. Данные для текстурных блоков хранятся в видеопамяти, их можно считывать оттуда и записывать. Поскольку TMU уже не являются внешними вычислительными блоками в полном понимании, а встроены в конвейер рендеринга, каждый текстурный блок может обрабатывать объекты по нескольку раз.
Действительно, для рендеринга объекта простых текстур уже недостаточно, использование нескольких слоев позволяет, например, получить 3D-эффект вместо плоской текстуры. Раньше объекты приходилось рассчитывать на конвейере несколько раз, и каждый проход текстурный блок накладывал текстуру, сегодня достаточно одного процесса рендеринга, текстурный блок может получать данные объекта для многократной обработки из буфера.
Контроллер памяти
Высокая пропускная способность памяти не менее важна, чем вычислительная производительность GPU. Только если данные можно будет быстро считывать из видеопамяти на GPU и записывать их обратно, вычисления будут проводиться достаточно быстро. На заднем плане здесь можно представить GPU, выполняющий вычисления, а на переднем - систему кэшей и памяти. Архитектуры GPU разрабатываются с учетом доступной пропускной способности памяти, иногда им необходима высокая пропускную способность, но в других случаях зависимость, напротив, снижается. Впрочем, как правило, производители пытаются добиться самой высокой пропускной способности памяти. И контроллер памяти здесь имеет решающее значение.
Помимо изменений в SM, новая архитектура NVIDIA получила оптимизированную структуру конвейеров растровых операций (ROP), а также соединения ROP и контроллера памяти. До поколения Turing ROP всегда подключались к интерфейсу памяти. И на каждый 32-битный контроллер памяти приходилось восемь ROP. Если число контроллеров памяти и ширина шины менялись, то же самое касалось и ROP. В архитектуре Ada Lovelace ROP перенесены в GPC. Используются два раздела ROP на GPC, каждый раздел содержит восемь ROP.

Что дает иную формулу вычисления ROP на GeForce RTX 4090. 11 GPC с 2x 8 ROP на каждом дают 176 ROP. У GeForce RTX 4080 работают семь GPC с 2x 8 ROP, что дает 112 ROP. NVIDIA намеренно интегрировала ROP глубже, чтобы задняя часть конвейера рендеринга меньше зависела от интерфейса памяти. Например, видеокарта GeForce RTX 4080 использует 256-битный интерфейс памяти, но содержит 112 ROP, а не 64 ROP.
Интерфейс памяти разделен на 32-битные блоки. В зависимости от желаемой ширины интерфейса памяти или емкости, их можно набирать в произвольном количестве.
Кэши L1 и L2
Размер кэша L1 составляет 128 кбайт для четырех SM. Однако кэш L2 значительно больше. Полный графический процессор AD102 имеет кэш L2 емкостью 98.304 кбайт, то есть почти 100 Мбайт. В стадии расширения GeForce RTX 4090 GPU имеет 73.728 кбайт. У GPU GA102 было всего 6.144 кбайт кэша L2. Как видим, NVIDIA увеличила кэш L2 в 12 раз и, конечно, надеется минимизировать «узкие места» при доступе к видеопамяти.
Ядра RT третьего поколения
Блоки трассировки лучей 3-го поколения или RT-ядра Ada Lovelace имеют вдвое большую пропускную способность, чем их предшественники, увеличивая производительность трассировки лучей до 2,8 раз. Для GeForce RTX 4090 это теоретически означает 191 RT TFLOPS, по сравнению с 78 RT TFLOPS для GeForce RTX 3090 Ti.
Кроме того, ядра RT 3-го поколения получили такие функции, как Opacity Micro-Map Engines и Micro-Mesh Engines. Это новые специализированные аппаратные блоки, которые ускоряют наиболее требовательные нагрузки трассировки лучей.
Мы хотели бы рассказать о Opacity Micro-Map Engines и Micro-Mesh Engines более подробно.
Opacity Micro-Maps представляют собой оптимизацию расчета трассировки лучей. Трассировка лучей не очень хорошо справляется с некоторыми объектами, например, листвой и растительностью. Лучи могут отражаться в бессчетных направлениях между листьями и ветвями, поэтому подобные объекты значительно осложняют трассировку. Третье поколение ядер RT может использовать Opacity Micro-Maps для присвоения статуса прозрачности подобным элементам, которые могут быть непрозрачными, прозрачными или неизвестными. Для сложных объектов ранее трассировка лучей не использовалась или применялась в облегченном виде. Opacity Micro-Maps должны учитывать подобные объекты в будущем.

Ядра RT третьего поколения генерируют Displaced Micro-Meshes (DMM). Дерево BVH (bounding volume hierarchies), которое используется для трассировки лучей, будет строиться до 10 раз быстрее и потреблять в 20 раз меньше видеопамяти. NVIDIA описывает DMM следующим образом: «DMM – это новые примитивы, представляющие собой структурированную сетку микротреугольников, которые вычислительные блоки RT 3-го поколения обрабатывают нативно. В результате снижаются требования к памяти и вычислительной производительности при рендеринге сложной геометрии с использованием простых треугольников по сравнению с предыдущими поколениями».
Ядра Tensor 4-го поколения и DLSS 3
Технология Deep Learning Super Sampling в третьей версии получила различные оптимизации. Улучшенные ядра Tensor четвертого поколения обеспечивают рост вычислительной производительности FP8 до 5x по сравнению с ядрами Tensor третьего поколения.

В DLSS 3 используются так называемые ускорители Optical Flow (OFA). Они вычисляют данные о движении пикселей из нескольких кадров для нейронной сети DLSS. Однако мы еще вернемся к этому в контексте DLSS 3 и реконструкции лучей, а также генерации кадров.
Shader Execution Reordering
Shader Execution Reordering (SER) используется для эффективного объединения вычислений в конвейере, чтобы вычислительные блоки всегда были задействованы максимально эффективно. SER позволяет повысить производительность выполнения шейдеров в 2 раза и увеличить частоту кадров в игре на 25%.
С третьей версией DLSS NVIDIA представляет совершенно новый метод, который является логическим развитием Deep Learning Super Sampling (DLSS).
Вместо того чтобы просчитывать кадр в низком разрешении и затем масштабировать его до целевого разрешения (включая реконструкцию ИИ), DLSS 3 регенерирует полные кадры с помощью Optical Multi Frame Generation. Без аппаратного ускорения генерация полных кадров невозможна, здесь используются ядра Tensor и ускорители Optical Flow (OFA) в ядрах RT.
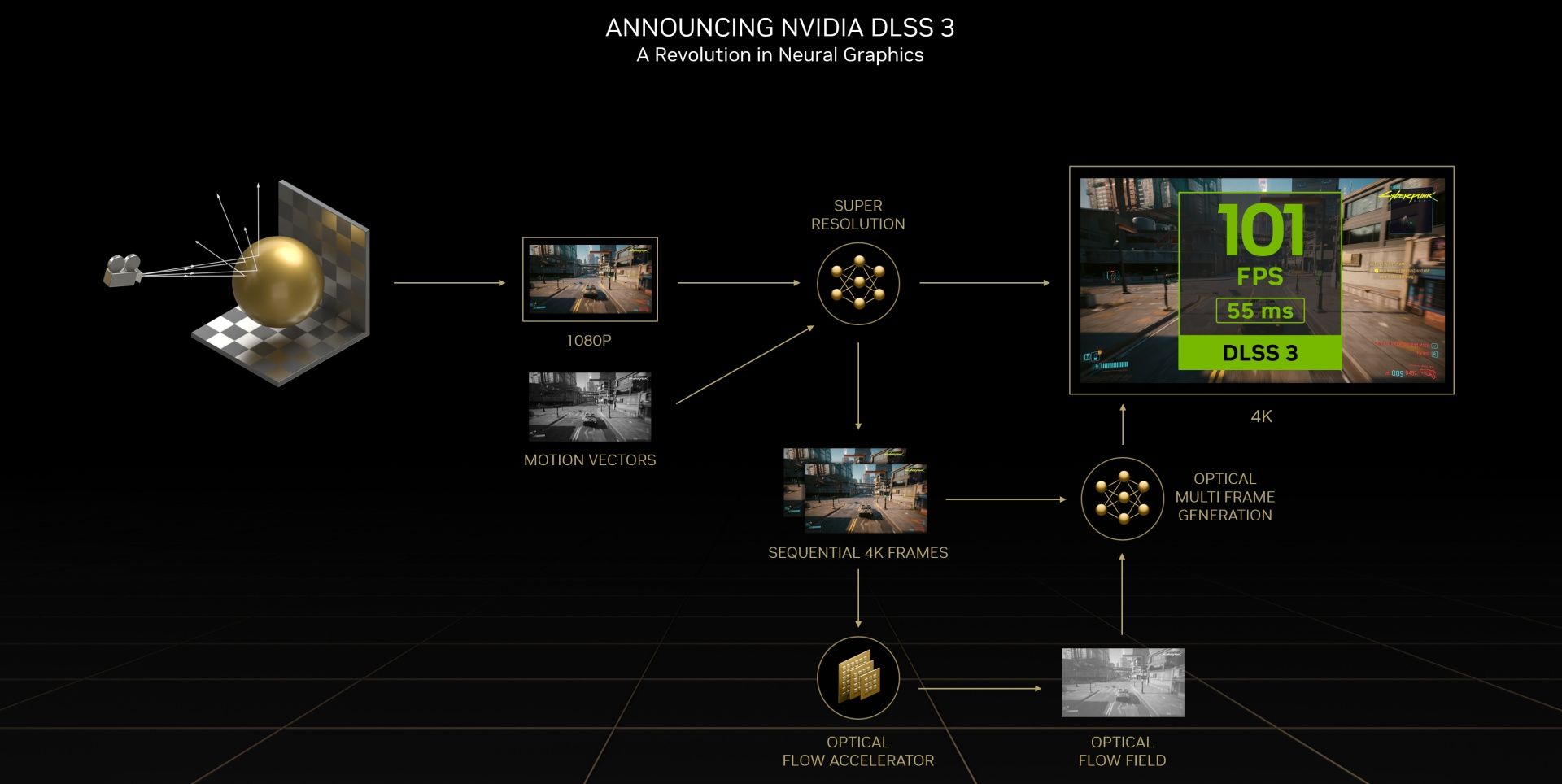
Для создания кадра необходимы следующие составляющие: текущий и предыдущий кадр, так называемое поле Optical Flow, создаваемое ускорителями в ядрах RT, и некоторые сведения от игрового движка, такие как векторы движения и информация глубины.

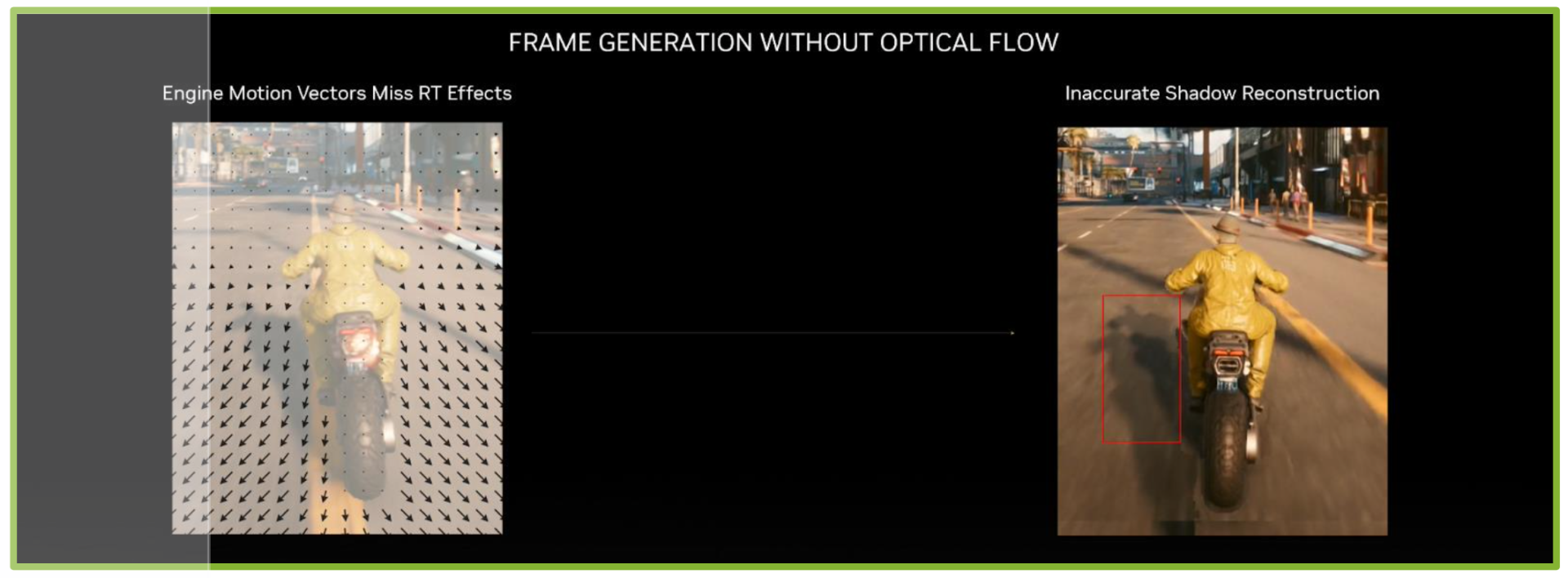
Если ускоритель Optical Flow отслеживает эффекты на пиксельном уровне, то на уровне геометрии DLSS 3 получает информацию о векторах движения (Motion Vectors) от игрового движка для точного отслеживания движения геометрии в сцене. На примере выше векторы движения показывают, как перемещается дорожное покрытие по отношению к мотоциклисту, но не учитывают его тень. Если создавать кадр на основе только векторов движения, то будут ошибки рендеринга, например, в виде некорректной тени. Поэтому необходим дополнительный анализ, который и выполняют ускорители Optical Flow.
Для каждого пикселя сеть DLSS Frame Generation на основе искусственного интеллекта определяет, как использовать информацию векторов движения игры, поля Optical Flow и выводимые игрой кадры для создания собственных кадров. Благодаря векторам движения игры и полю Optical Flow сеть Frame Generation может точно отслеживать движение объектов, восстанавливать геометрию и эффекты.
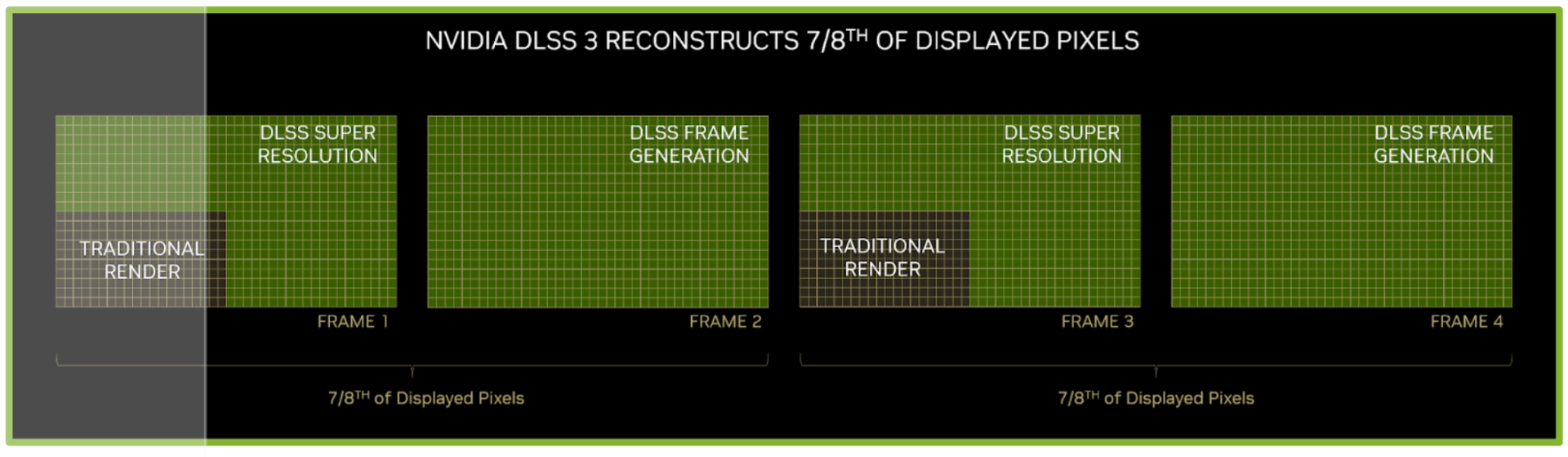
DLSS 3 – многослойная реализация DLSS. Сначала с помощью DLSS Super Resolution создается кадр в четверти от разрешения монитора (например, 1.920 x 1.080 вместо 3.840 x 2.160 пикселей). Второй кадр создается уже через DLSS Frame Generation. Для третьего кадра вновь используется DLSS Super Resolution, а для четвертого - DLSS Frame Generation. Таким образом, только 1/8 пикселей, которые будут выведены на дисплей, проходят непосредственно через классический рендеринг и потоковые процессоры.
DLSS 3 работает вместе с NVIDIA Reflex. GPU и CPU синхронизируются, чтобы обеспечить минимальные системные задержки. Таким образом, DLSS 3 обещает уменьшить задержки в два раза.
DLSS 3 также дает преимущество в играх, которые упираются в ограничения СPU, не способных выдавать высокую частоту кадров. В данном случае меняется классическая зависимость от CPU или GPU. В подобных ситуациях NVIDIA ожидает, как минимум, двукратный прирост частоты кадров, поскольку каждый второй кадр создает видеокарта.
DLSS 3 работает только на видеокартах GeForce RTX 40, поскольку зависит от ускорителей Optical Flow архитектуры Ada Lovelace. DLSS Super Resolution, с другой стороны, продолжит работать и на видеокартах GeForce RTX 30 и GeForce RTX 20. Технология Reflex поддерживается и на предыдущих поколениях видеокарт, NVIDIA здесь спускается вплоть до линейки GeForce GTX 900.
DLSS 3.5: Реконструкция лучей
В DLSS 3.5 NVIDIA делает еще один шаг и убирает фильтр подавления шумов, который часто снижал визуальное качество. В DLSS 3.5 отсутствующая информация или пиксели по-прежнему будут добавляться через искусственный интеллект. Без ИИ не обойтись, поскольку производительности самых быстрых видеокарт GeForce RTX (RTX 4090) все равно недостаточно, чтобы вывести все пиксели через трассировку лучей. Сама по себе технология DLSS использует рендеринг с меньшим разрешением, пикселей получается меньше, и отсутствующие пиксели раньше добавлялись с помощью фильтра подавления шумов.



Фильтры подавления шумов используют разные способы, чтобы устранить недостаток информации. Можно использовать информацию предыдущих кадров, а также интерполировать соседние пиксели. Но все эти способы необходимо вручную дорабатывать и оптимизировать, чтобы получить приемлемый результат по качеству картинки. Но даже в этом случае все равно достичь идеала невозможно.
NVIDIA приводит в качестве примеров временные артефакты, некорректное вычисление освещения и ухудшение качества картинки из-за отсутствия информации.

С новой версией DLSS 3.5 выполняется реконструкция лучей (Ray Reconstruction). Используются кадры 4K и лучи, рассчитанные с высокой частотой. Они позволяют реконструировать кадр из низкого разрешения. При этом учитываются векторы движения игры. Кадр высокого разрешения создается с помощью реконструкции лучей и их масштабирования до нужного разрешения, также используются временные данные предыдущих кадров. Разница с предыдущей реализацией в том, что эффекты трассировки лучей тоже частично рассчитываются с помощью ИИ, что позволяет выводить их с более высоким качеством.
Нейросеть NVIDIA уже натренирована на реконструкцию трассировки лучей для разных эффектов. Разработчикам не нужно больше оптимизировать фильтр подавления шумов – DLSS 3.5 все сделает автоматически.
NVIDIA показала улучшенный рендеринг на примере выше. Вместо потери тени под объектом DLSS 3.5 выводит ее корректно.
В отличие от Frame Generation, реконструкция трассировки лучей работает не только на видеокартах GeForce RTX 40, но и на всех моделях предыдущих поколений RTX. Но Frame Generation остается прерогативой поколения Ada Lovelace.

Cyberpunk 2077 Phantom Liberty и Alan Wake 2 - первые две игры, которые уже поддерживают DLSS 3.5. В 2024 году ожидается еще много игр.
Полный рендеринг кадра с помощью трассировки лучей является весьма заманчивой целью. Он позволит реалистично вывести свет, тени, отражения и преломления. Разработки в сфере трассировки лучей начались еще в конце 1970-х, но до сих пор вывести всю сцену через трассировку лучей в реальном времени не представлялось возможным. В киноиндустрии различные технологии трассировки лучей используются многие годы, но на рендеринг кадра уходят от нескольких минут до многих часов, говорить о реальном времени не приходится.

С архитектурой Ampere и ядрами RT второго поколения NVIDIA увеличила производительность трассировки лучей. Более важно то, что эффекты трассировки лучей сегодня поддерживаются не только на ПК, но и на двух современных поколениях консолей Microsoft (Xbox Series X) и Sony (PlayStation 5). Поэтому база для игровых разработчиков значительно расширилась, эффекты больше не ограничены ПК.
Как работает трассировка лучей?
По названию «трассировка лучей» сразу же можно понять принцип работы технологии. Лучи исходят от источника света, после чего попадают в глаз зрителя. Но на самом деле все ровно наоборот, в компьютерной графике используется обратный порядок трассировки лучей (Backward Ray Tracing). То есть расчет идет от глаза зрителя до объектов сцены и источника света.
В первую очередь трассировка лучей – это способ проверки видимости объекта. Его цель – определить, виден ли объект зрителю или нет. Расчет с помощью луча выполняется для каждого пикселя, расположенного на плоскости экрана, начиная от глаза зрителя. В результате расчет выполняется для всех видимых объектов (примитивов) в 3D-пространстве. И с помощью геометрических методов каждый пиксель на плоскости экрана проверяется на наличие видимых и невидимых объектов с точки обзора.

Кроме проверки видимости объектов, трассировка лучей позволяет добавить на сцену и другую информацию. В частности, освещение. Для этого используются свойства материала всех примитивов. Матовая поверхность или глянцевая? Какой угол отражения, степень прозрачности или рассевания света? Также используются и другие параметры, которые описывают поведение поверхности. Легко посчитать, что число лучей экспоненциально увеличивается по мере усложнения сцены. Видеокарты GeForce RTX 40 по-прежнему не могут рассчитывать трассировку лучей в реальном времени для полного кадра в разрешении UHD, если требуется учитывать несколько сотен или даже тысяч примитивов со своими свойствами отражения и рассеяния. Конечно, есть некоторые исключения с полной реализацией RT, а именно Quake II RTX или Minecraft с трассировкой лучей. Однако эти игры не такие тяжелые для классической технологии растеризации.
Существуют также некоторые приемы, позволяющие снизить вычислительные усилия. Среди них - локальные модели освещения или предопределенные описания источников света, упрощающие расчет.
На проверке видимости объектов и расчете освещения возможности трассировки лучей не ограничиваются. Лучи можно проложить не только в обратном порядке, от зрителя через экран к источнику света. Но и из любой точки пространства. Что как раз позволяет рассчитывать тени. Тень создается в том случае, если между точкой поверхности и источником света имеется препятствие. Конечно, в реальности одним источником света дело не ограничивается. Отражения и рассеивания света приводят к появлению мягких и жестких теней, а также других эффектов, в зависимости от расстояния. В случае классического рендеринга могут использоваться заранее подготовленные карты теней (предварительно рассчитанные, что весьма сложно для крупных сцен и масштабных 3D-миров), либо определенные технологии, такие как Enhanced Horizon Based Ambient Occlusion (HBAO), Hybrid Frustum Traced Shadows (HFTS) и т.д. Но все они являются лишь приближением к реалистичному расчету теней.
Еще сложнее трассировка лучей становится в случае полупрозрачных, прозрачных и отражающих объектов. В точках пересечения сред появляются дополнительные лучи, поэтому расчетов становится больше. До сих пор те же отражения были возможными только при использовании определенных хитростей в процессе рендеринга, поскольку если отраженные объекты располагались за пределами видимого пространства, то они отсекались от процесса рендеринга раньше, поэтому и расчет не представлялся возможным.
В случае отражающих поверхностей следует учитывать отраженные лучи (угол падения равен углу отражения). Если же объект прозрачный, то необходимо опираться на законы преломления. Кроме того, прозрачные объекты отражают часть света, а не только преломляют. Эти дополнительные лучи увеличивают сложность сцены и необходимые вычисления.
Вторичные лучи тоже могут отражаться/преломляться, так что трассировка лучей используется рекурсивно для создания множественных отражений и преломлений. NVIDIA показала данную функцию в некоторых демонстрациях. Рекурсивная трассировка лучей была разработана еще в 1980-х годах, но только теперь она получила техническую реализацию NVIDIA. Причем рекурсивная трассировка лучей позволяет вывести не только множественные отражения и преломления света, но и тени. Игровые движки часто рассматривают источники света как точки. Но в реальности источники света имеют определенный размер, что приводит к размытию теней. Для расчета мягких теней вместо одного луча просчитываются несколько, после чего принимается среднее значение. Такой подход позволяет создавать основную тень и полутень. Недостатком можно назвать появление шума, если используется слишком мало лучей.

Последний момент - трассировка пути Path Tracing, расчеты лучей выполняются не только из глаза зрителя, но и от источников света. Сочетание разных способов позволяет максимально реалистично вывести сцену. Но трассировка пути требует значительных вычислительных ресурсов, поэтому реализация ограничена лишь некоторыми играми, да и детализация урезана.
Сочетание разных технологий трассировки еще больше увеличивает нагрузку, даже на новых видеокартах GeForce RTX говорить рендеринге полной сцены в реальном времени преждевременно. Пока что NVIDIA предлагает через интерфейс DirectX следующие эффекты:
- Отражения и преломления
- Тени и освещение
- Глобальное освещение
- Расчеты физики, определение коллизий, симуляция частиц
- Симуляция аудио (NVIDIA VRWorks Audio)
- In-Engine Path Tracing
Игры обычно используют лишь часть приведенных эффектов. Но разработчики не сидят, сложа руки. В Metro: Exodus изначально появились лишь самые простые расчеты теней и глобального освещения через трассировку лучей. Но в Enhanced Edition набор эффектов был расширен, теперь, в частности, поддерживается расчет нескольких отражений луча.
Каждая high-end видеокарта нуждается в соответствующем программном обеспечении, поскольку оно может предложить пользователю дополнительные преимущества, которые не стоит игнорировать. ZOTAC, например, предлагает программное обеспечение Firestorm, которое позволяет управлять видеокартой в рамках спецификаций NVIDIA.
В серии GeForce RTX 40 ZOTAC пересмотрела пользовательский интерфейс.

На центральном дашборде производительности можно настроить частоту Boost и базовую GPU. Также можно изменить тактовую частоту памяти. Есть возможность увеличить напряжение GPU на 0,1 В. Таким образом, пользователь может вручную оптимизировать производительность видеокарты, но можно воспользоваться автоматическим сканером OC.
Для дальнейшей оптимизации температур и уровня шума видеокарты можно настроить предельную мощность Power Limit и целевую температуру.


На странице состояния можно отслеживать самые важные системные параметры видеокарты. Помимо тактовых частот в реальном времени, также отображаются температура, напряжение и уровень нагрузки. Отдельно можно посмотреть скорость вращения вентиляторов.
Если вас не устраивают настройки графиков вентиляторов, и вы хотите изменить их самостоятельно, утилита ZOTAC Firestorm это позволяет. Доступен как автоматический режим, так и полностью ручной с фиксированными скоростями или заданным графиком работы вентиляторов.
Инструменты NVIDIA
В экосистеме NVIDIA центральным элементом является GeForce Experience. Начнем с оптимизации игровых настроек через GeForce Experience. В играх обычно доступны множество настроек качества графики и производительности помимо разрешения. Конечно, есть готовые пресеты, облегчающие задачу настройки игры под доступные аппаратные ресурсы, но NVIDIA знакома со своими видеокартами лучше всех, поэтому компания решила поделиться знаниями через GeForce Experience.
Утилита позволяет оптимизировать игровые настойки кликом мыши. Конечно, пользователь может отредактировать какие-либо настройки по своему вкусу. Здесь NVIDIA опирается на опыт миллионов пользователей, которые готовы поделиться с сообществом идеальными игровыми настройками, если можно так сказать.
Но GeForce Experience - не просто утилита настройки игр. Пользователь получает сообщения об обновлениях драйвера, новости из мира GeForce, есть и возможность мониторинга системы во время игры.



В утилиту GeForce Experience интегрирована поддержка Shadowplay. Можно записывать игровой стрим напрямую на видеокарте без дополнительных утилит, после чего передавать поток на такие платформы, как Twitch, Twitch и Facebook. NVIDIA Highlights автоматически определяет и захватывает особые моменты в игре. Все это осуществляется с минимальной нагрузкой на процессор, поэтому не придется идти на компромиссы по качеству записи или удобству из-за недостаточных ресурсов. Суть здесь в том, что кодирование/декодирование осуществляется напрямую на GPU, причем поддерживается большая часть современных кодеков.
Через NVIDIA Ansel можно получать кадры кинематографического качества благодаря специальному фоторежиму рендеринга, после чего ими можно делиться в Facebook, Google Photos или Imgur. В поддерживаемых играх можно выбирать супер-разрешение, панораму на 360 градусов, HDR и стереоскопическое видение, причем через фильтры Freestyle можно накладывать различные эффекты в реальном времени на видео геймплея.
Скачать утилиту NVIDIA GeForce Experience можно здесь.
NVIDIA Broadcast
Для тех геймеров, которые хотят делиться контентом более профессионально, NVIDIA разработала утилиту Broadcast. Она позволяет превратить любую комнату в домашнюю студию стриминга.
Видеороликами геймплея сегодня никого не удивишь, но в них не так просто вставить самого геймера или дополнительные эффекты и звук. Подобная сборка для стриминга стоит круглую сумму, которую придется потратить как на аппаратное, так и программное обеспечение. Но с утилитой Broadcast NVIDIA позволяет неплохо сэкономить. Например, уже встроена функция подавления шумов, которая отлично справляется с фильтрацией шума нажатий клавиш, дыхания, вентиляторов ПК, реверберацией и другими помехами. Подавление шумов и эха осуществляется с помощью искусственного интеллекта.
В стриминг можно добавлять эффекты и картинки, не требующей сложных конфигурацией. Можно размыть или убрать фон за геймером, перенести изображение, и это только часть возможностей. Здесь NVIDIA тоже опирается на современные технологии искусственного интеллекта, способные определить фон за геймером и заменить его виртуальным по нажатию кнопки.
Зрители увидят не только геймплей, но и живую реакцию самого геймера в напряженных игровых битвах. Причем профессиональное оборудование съемки не потребуется, функция Auto Frame будет следить за положением геймера в реальном времени. Обрезка и зум выполняются автоматически, поэтому геймер всегда будет выводиться корректно.
В условиях скудного освещения функция подавления шумов помогает улучшить качество картинки. Опять же, дорогого оборудования здесь не требуется.
Утилиту NVIDIA Broadcast можно скачать здесь.
NVIDIA Reflex
Конечно, fps - характеристика важная, но не исчерпывающая. Специально для турниров NVIDIA разработала технологию Reflex, которая призвана обеспечить геймерам конкурентное преимущество. Суть здесь в том, чтобы дать минимально возможные задержки между действием геймера и игрой. Тому способствуют видеокарты GeForce RTX и мониторы G-Sync.
NVIDIA Reflex снижает задержки на системном уровне благодаря динамическому взаимодействию с GPU и игровыми оптимизациями. Цель в том, чтобы между кликом мышью и реакцией на него в игре проходило как можно меньше времени. Что позволит геймеру раньше выявить потенциальные цели и быстрее на них отреагировать. Конечно, Reflex положительно сказывается и на точности прицеливания.
NVIDIA Reflex показывает преимущество не только при сравнимой частоте кадров, но и на высоких fps. В турнирных играх, таких как Apex Legends, Valorant, Fortnite и многих других частота кадров может достигать нескольких сотен fps. Обычно геймерам приходится ждать вывода кадра в очереди, но Reflex SDK снижает очередь рендеринга до уровня, при котором минимизируются задержки ввода. Все это синхронизируется с работой процессора и GPU. Команды мыши или клавиатуры добавляются в ту часть очереди рендеринга, которая гарантирует максимально быструю обработку.
Чтобы геймерам была более понятна данная тема, NVIDIA выпустила Reflex Latency Analyzer, который встроен в последние дисплеи G-Sync. Reflex Latency Analyzer определяет финальную системную задержку, что позволяет получить представление о производительности и лагах. Мы провели тесты Reflex в сочетании с монитором ASUS ROG Swift PG259QNR и мышью ROG Chakram Core.
Подписывайтесь на группу Hardwareluxx ВКонтакте и на наш канал в Telegram (@hardwareluxxrussia).