

 На конференции GPU Technology Conference NVIDIA обычно не представляла новые архитектуры GPU. Компания использовала GTC для уточнения планов по грядущим GPU и Tegra, а также рассказывала о новых технологиях. На этот раз NVIDIA пошла другим путем, представив Tesla P100. Перед нами новый GPU на архитектуре Pascal. Дженсен Хуанг перед представлением нового продукта рассказал о затратах на разработку архитектуры Pascal и Tesla P100, которые составили 2-3 млрд. долларов США. Конечно, NVIDIA не дает точного значения, чтобы не делиться лишней информацией с конкурентами. Подробности здесь разглашаются редко.
На конференции GPU Technology Conference NVIDIA обычно не представляла новые архитектуры GPU. Компания использовала GTC для уточнения планов по грядущим GPU и Tegra, а также рассказывала о новых технологиях. На этот раз NVIDIA пошла другим путем, представив Tesla P100. Перед нами новый GPU на архитектуре Pascal. Дженсен Хуанг перед представлением нового продукта рассказал о затратах на разработку архитектуры Pascal и Tesla P100, которые составили 2-3 млрд. долларов США. Конечно, NVIDIA не дает точного значения, чтобы не делиться лишней информацией с конкурентами. Подробности здесь разглашаются редко.

Но сначала поговорим о вычислительной производительности Tesla P100: 5,3 TFLOPS с вычислениями FP64, 10,6 TFLOPS с вычислениями FP32 и 21,2 TFLOPS с вычислениями FP16 – последний показатель наиболее важен для сетей глубокого обучения (Deep Learning). P100, непосредственно сам GPU, состоит из 15,3 млрд. транзисторов, что в два раза больше, чем у GM200 на архитектуре Maxwell. Модуль целиком, то есть GPU с памятью и подложкой, содержит уже 150 млрд. транзисторов. Чип оснащен 14 Мбайт общей памяти, которая работает как регистровый кэш. Регистры доступны для всего GPU с пропускной способностью 80 Тбайт/с. Добавьте к этому 4 Мбайт кэша L2.
NVIDIA пока не комментирует количество потоковых процессоров, но, по крайней мере, назван тип памяти и объем. NVIDIA использовала для Tesla P100 память HBM 2-го поколения объемом 16 Мбайт. NVIDIA указывает, что первые платы Tesla P100 уже производятся и поставляются клиентам. Похоже, что Samsung смогла более существенно увеличить производство памяти, чем планировалось ранее. Дженсен Хуанг со сцены сообщил, что GPU и память соединяются более чем 4.000 проводниками. Что с учетом 4.096-битной шины памяти не удивляет. NVIDIA указывает пропускную способность памяти 720 Гбайт/с. Сам GPU производится по 16-нм техпроцессу FinFET, скорее всего TSMC. Также TSMC отвечает за установку GPU и памяти на подложку. Тайваньская компания разработала технологию CoWoS (Chip-on-Wafer-on-Substrate), в результате NVIDIA может получать от TSMC уже готовые модули, а AMD приходится обращаться к сторонним компаниям. Технологию AMD мы поясняли в отдельной статье.

В таблице приведены технические спецификации Tesla P100 по сравнению с ранее представленными high-end потребительскими видеокартами AMD и NVIDIA. Сравнение проводить нелегко, поскольку категории продуктов разные, но оценку дать можно.
| Обзор технических спецификаций Tesla P100 | |||
|---|---|---|---|
| Модель | NVIDIA Tesla P100 | AMD Radeon R9 Fury X | NVIDIA GeForce GTX 980 Ti |
| Цена | - | от 50 тыс. рублей от 615 евро |
от 45 тыс. рублей от 620 евро |
| Сайт производителя | NVIDIA | AMD | NVIDIA |
| Техническая информация | |||
| GPU | P100 | Fiji XT | GM200 |
| Техпроцесс | 16 нм | 28 нм | 28 нм |
| Число транзисторов | 15,3 млрд. | 8,9 млрд. | 8 млрд. |
| Тактовая частота GPU (базовая) | 1.328 МГц | - | 1.000 МГц |
| Тактовая частота GPU (Boost) | 1.480 МГц | 1.050 МГц | 1.075 МГц |
| Частота памяти | 737 МГц | 500 МГц | 1.750 МГц |
| Тип памяти | HBM2 | HBM | GDDR5 |
| Объём памяти | 16 GB | 4 GB | 6 GB |
| Ширина шины памяти | 4.096 бит | 4.096 бит | 384 бит |
| Пропускная способность памяти | 720 Гбайт/с | 512,0 Гбайт/с | 336,6 Гбайт/с |
| Версия DirectX | 12 | 12 | 12 |
| Потоковые процессоры | 3.584 | 4.096 | 2.816 |
| Текстурные блоки | 224 | 256 | 176 |
| Конвейеры растровых операций (ROP) | - | 64 | 96 |
| Тепловой пакет | 300 Вт | 275 Вт | 250 Вт |
| SLI/CrossFire | - | CrossFire | SLI |
По прошлому году нам уже известны такие функции, как Mixed Precision, NVLink и 3D Memory/HBM2. Ниже мы вкратце напомним их суть.
Mixed Precision

В SoC Tegra X1 NVIDIA встроила GPU "Maxwell" с поддержкой "Double Speed FP16". Предыдущие архитектуры "Fermi" и "Kepler", как и "Maxwell" используют выделенные ядра CUDA FP32 и FP64. Есть они и в кластере "Maxwell" на SoC Tegra X1. Но в данном сегменте расчеты FP16 более важны. Поэтому NVIDIA изменила обработку команд FP16, чтобы они могли выигрывать от выделенных ядер FP32. Команды FP16 соединяются, чтобы их можно было выполнять на ядрах FP32. Но команды FP16 могут объединяться, если они выполняют одинаковые вычисления. Например, можно объединить две команды сложения или две команды умножения. Операции FP16 под Android довольно важны в играх, а также при анализе фотографий и видео.
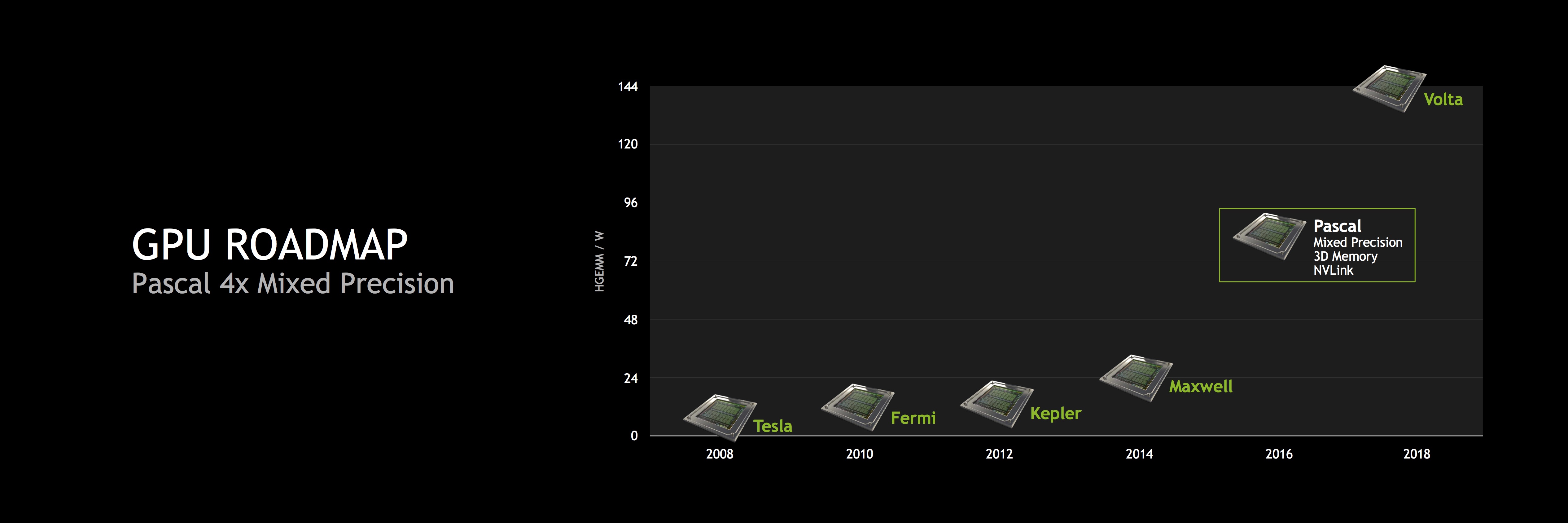
Какое отношение эта технология имеет к "Pascal"? В новой архитектуре "Pascal" технология Mixed Precision будет интенсивно использоваться GPU для разных нужд. Технология уже использовалась в потоковых процессорах Tegra X1. Раньше технологии сначала появлялись в GPU GeForce, после чего переносились в SoC Tegra, но теперь мы получаем обратное направление – новинки в SoC Tegra появляются в грядущих архитектурах GPU. В Tegra X1 группируются операции FP16, которые важны в сфере обработки видео и фотографий. Android Display Composer тоже опирается на команды FP16, именно по этой причине в Tegra X1 столь большое внимание было уделено данным вычислениям. Но почему NVIDIA реализовала подобную технологию в "Pascal"? Скорее всего, NVIDIA планирует существенно увеличить производительность FP16. В частности, от высокой производительности FP16 выигрывают сети глубокого обучения (Deep Learning). NVIDIA говорит о четырёхкратном увеличении по сравнению с "Maxwell". Нам ещё предстоит увидеть, насколько выиграют от данной технологии геймеры.
NVLink
NVLink является важной частью современных и будущих систем HPC на GPU NVIDIA. IBM запланировала поддержку NVLink в своих процессорах и частично уже реализовала. NVIDIA активно продвигает программу лицензирования NVLink, та же HP уже выпускает серверы с NVLink, и NVIDIA проводит переговоры со своими многочисленными партнерами.
Технология 3D Stacked Memory или High Bandwidth Memory устраняет "узкое место" между GPU и видеопамятью. Интерфейс NVLink призван революционизировать соединение между GPU и CPU, а также между несколькими GPU. В данном отношении на первом месте находится высокая пропускная способность, которая сегодня обеспечивается распространённым интерфейсом PCI Express. 16 линий PCI Express 3.0 обеспечивают пропускную способность 15,75 Гбайт/с или 128 GT/s. Кроме того, NVIDIA с архитектурой "Maxwell" добавила технологию сжатия памяти, которая призвана удовлетворить растущие требования к пропускной способности памяти.
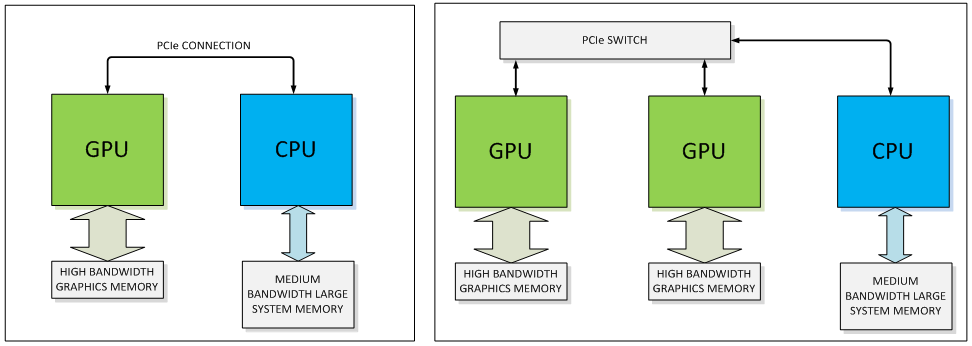
По информации NVIDIA, интерфейс NVLink в пять-двенадцать раз быстрее. Поэтому пропускная способность составляет 80-200 Гбайт/с. Но не следует забывать и конкуренте PCI Express 4.0, который вновь удваивает пропускную способность PCI Express 3.0 до уровня 31,51 Гбайт/с или 256 GT/s.
NVIDIA использует для NVLink соединение точка-точка. Одно соединение NVLink опирается на восемь линий. У "Pascal" изначально будут использоваться четыре соединения NVLink. По информации NVIDIA, количество соединений может изменяться в зависимости от целевого рынка - хотя это будет верно не столько для "Pascal", сколько для грядущих GPU. Соединения NVLink можно гибко комбинировать, если того требуют сценарии использования. Например, может использоваться простое соединение GPU-CPU, но также может быть задействована сеть соединений GPU-CPU и GPU-GPU.

Но кроме GPU поддерживать NVLink должен и CPU. Пока что только IBM объявила о поддержке интерфейса NVLink в процессорах PowerPC. По словам NVIDIA, компания обсуждает с производителями процессоров ARM идею добавить соответствующую поддержку к серверным решениям после представления "Pascal" на рынок. Конечно, NVIDIA разрабатывает собственную архитектуру CPU "Project Denver", которая была реализована в виде версии Tegra K1. Здесь вновь следует подчеркнуть, что NVLink первое время будет распространяться только на профессиональном сегменте. Для настольных компьютеров будет вариант видеокарт "Pascal" без интерфейса NVLink, но с поддержкой PCI Express. NVLink не сможет полностью заменить PCI Express даже в профессиональном окружении. По интерфейсу PCI Express будет передаваться информация управления и конфигурации, а через NVLink будут передаваться только данные для вычислений на GPU.
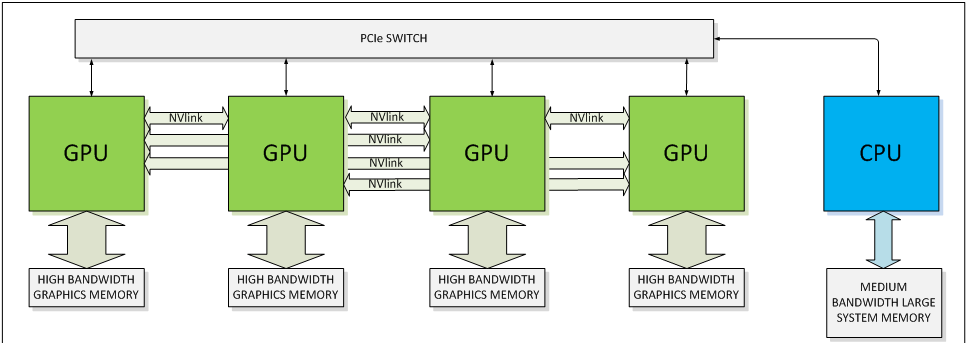
А теперь некоторая информация о NVLink применительно к GPU Pascal. Пока что NVIDIA не планирует представлять подобный модуль Pascal для классических настольных ПК формата ATX. Будет интересно узнать, какие перемены нас ждут в будущем. Возможно, NVIDIA планирует заменить классический дизайн видеокарт, и модуль Pascal является одним из шагов в данном направлении.
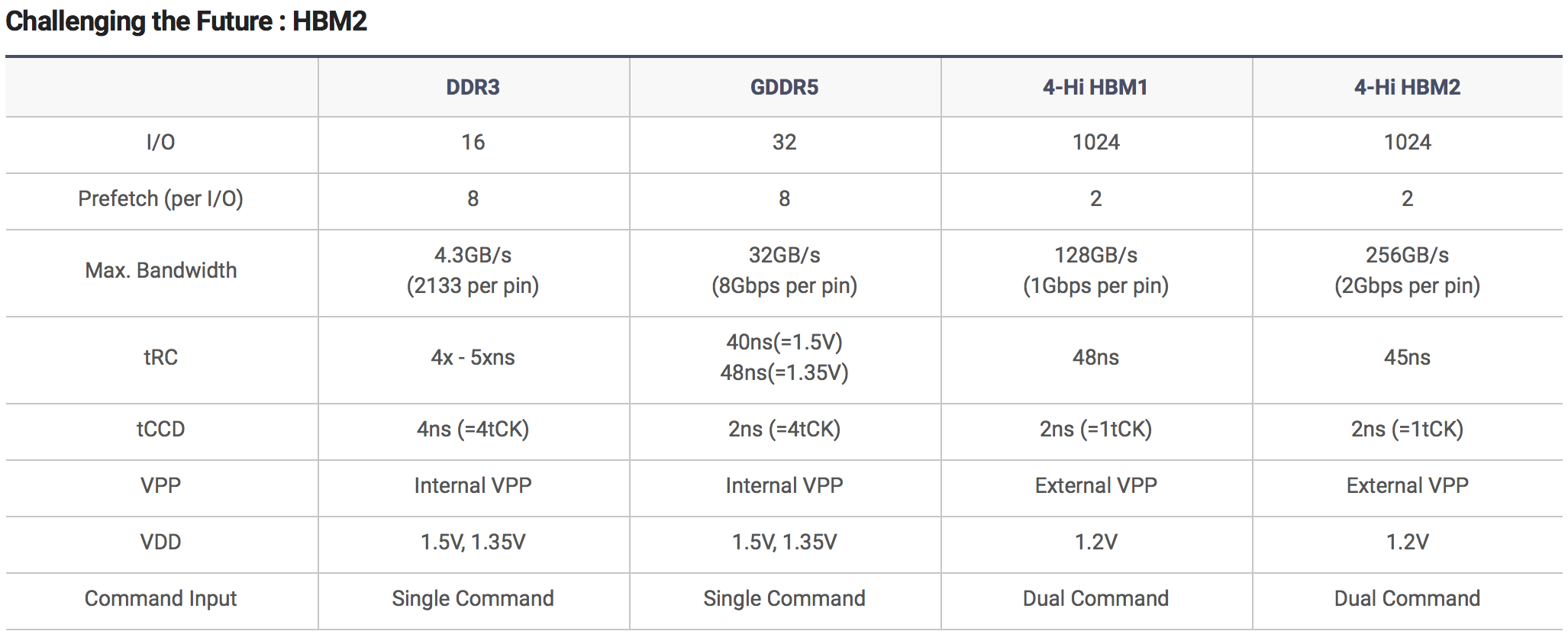
HBM2
Технологии Mixed Precision и NVLink не так интересны конечным пользователям, поскольку в играх они вряд ли себя проявят. Чего нельзя сказать о новой технологии памяти. Она является весьма интересной технической чертой нового поколения GPU от NVIDIA. При взаимодействии GPU и памяти очень важна высокая пропускная способность. AMD сделала первый шаг в прошлом году с памятью HBM и GPU Fiji. NVIDIA удивила многих своим анонсом, что Tesla P100 уже поставляется клиентам с памятью HBM2.

Согласно стандарту «JESD235 High Bandwidth Memory (HBM) DRAM standard» HBM2 состоит из 2, 4 или 8 слоев, таким образом, ёмкость одного чипа составит от 2 до 8 Гбайт. Поскольку 4 таких чипа уже использовались в GPU Fury, такое же количество чипов ожидается и у новых графических ускорителей Pascal, таким образом общий объем памяти у новых видеокарт составит до 32 Гбайт. В случае Tesla P100 объем составляет 16 GB.
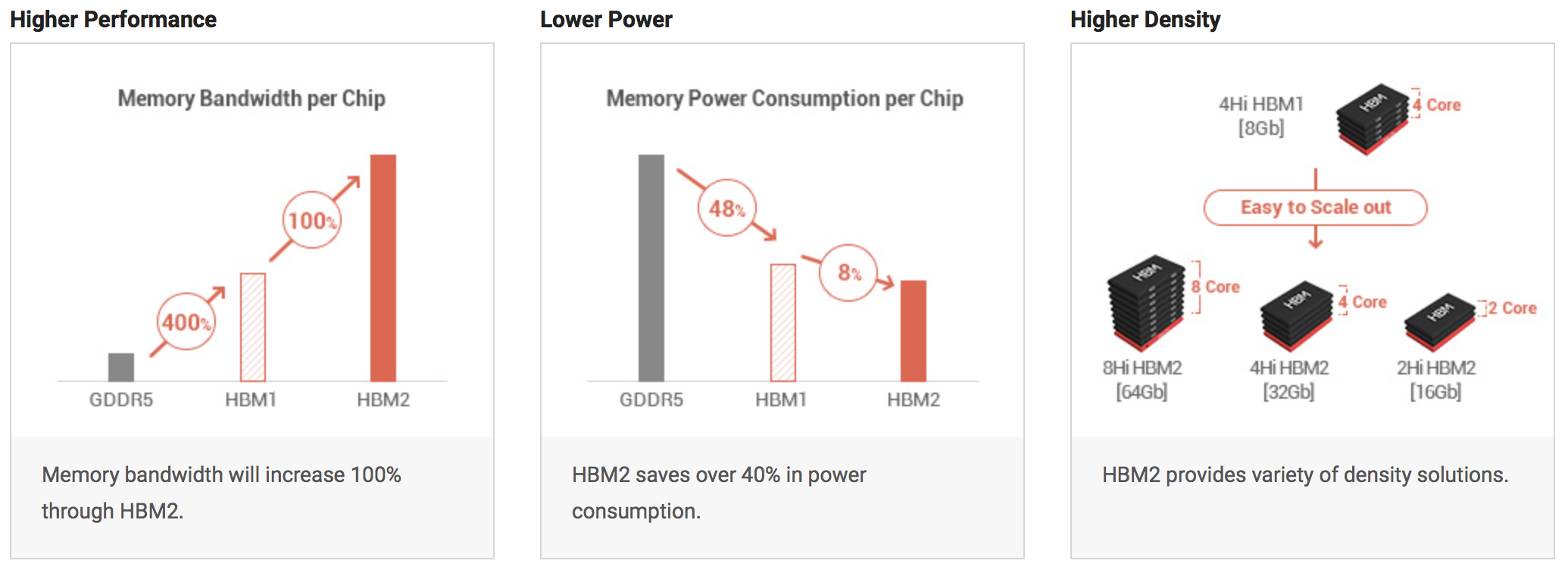
HBM2 позволяет использовать до 8 слоев объемом 1 Гбайт, получая общим объем чипа до 8 Гбайт. Кроме объема памяти значение имеет и её пропускная способность, которая у HBM2 стала ещё больше. Для этих целей тактовая частота была изменена с 500 до 1.000 МГц. Для 1024-битного интерфейса это означает увеличение пропускной способности вдвое – в то время, как Fiji с памятью HBM работала со скоростью 512 Гбайт/с, в будущих GPU скорость может составить до 1.024 Гбайт/с.
Таким образом, можно сказать, что HBM2 позволит производителям видеокарт увеличить пропускную способность вдвое, а объем памяти в 8 раз. Напряжение останется прежним и составит 1,2 В. У AMD уже есть опыт и налаженные связи для производства видеокарт с HBM. С технической точки зрения новая технология потребует больших усилий от производителей, но тем не менее, она весьма интересна, поэтому мы посвятили этой теме отдельную статью.
Мы опубликуем новые подробности с GTC 2016 в ближайшее время.