

 NVIDIA, наконец, соизволила поделиться первыми подробностями архитектуры Pascal. Также представлен и первый продукт: ускоритель вычислений Tesla P100. На пленарном докладе NVIDIA объявила некоторые подробности об архитектуре Pascal, которые мы хотели бы свести в одной статье. Ниже мы сфокусируемся на GPU GP100 на архитектуре Pascal. Дополнительную информацию о Tesla P100 вы можете найти в отдельной статье.
NVIDIA, наконец, соизволила поделиться первыми подробностями архитектуры Pascal. Также представлен и первый продукт: ускоритель вычислений Tesla P100. На пленарном докладе NVIDIA объявила некоторые подробности об архитектуре Pascal, которые мы хотели бы свести в одной статье. Ниже мы сфокусируемся на GPU GP100 на архитектуре Pascal. Дополнительную информацию о Tesla P100 вы можете найти в отдельной статье.
Начнем с производства. NVIDIA использует мощности TSMC и 16-нм техпроцесс. Площадь чипа составляет 610 мм². NVIDIA для GPU указывает 15,3 млрд. транзисторов, во всем модуле их число составляет 150 млрд. Но здесь NVIDIA учитывает и другие компоненты, такие как память, межсоединения и т.д. Память HBM2 NVIDIA устанавливает на подложку в количестве четырех чипов. Технология подложки обеспечивается TSMC, так что NVIDIA не приходится обращаться к сторонним производителям для установки компонентов на подложку.

Архитектура Pascal
Центральным компонентом архитектуры по-прежнему являются потоковые мультипроцессоры Streaming Multiprocessors (SM). Графический процессор состоит из кластеров GPC (Graphics Processing Cluster, потоковых мультипроцессоров SMS и контроллеров памяти. У GP100 мы получаем шесть GPC, десять SM, каждый содержит по 64 потоковых процессора. В результате число потоковых процессоров составляет 3.840 (6x10x64). Но это касается только полной версии GP100, у Tesla P100 используются только 56 SM, что приводит к 3.584 потоковым процессорам. Вокруг GPC организованы восемь контроллеров памяти с 512-битным интерфейсом. В результате GPU GP100 получает 4.096-битную шину с памятью HBM2. Кроме 64 потоковых процессоров в SM присутствует четыре текстурных блока, что дает 244 текстурных блока в сумме.
| Техническая информация GPU GP100 | |||
|---|---|---|---|
| GPU | GP100 | Fiji XT | GM200 |
| Техпроцесс | 16 нм | 28 нм | 28 нм |
| Число транзисторов | 15,3 млрд. | 8,9 млрд. | 8 млрд. |
| Частота памяти | 737 МГц | 500 МГц | 1.750 МГц |
| Тип памяти | HBM2 | HBM | GDDR5 |
| Объем памяти | 16 GB | 4 GB | 6 GB |
| Интерфейс памяти | 4.096 бит | 4.096 бит | 384 бит |
| Версия DirectX | 12 | 12 | 12 |
| Потоковые процессоры | 3.840 | 4.096 | 2.816 |
| Текстурные блоки | 224 | 256 | 176 |
| Конвейеры растровых операций (ROP) | - | 64 | 96 |
| Тепловой пакет | 300 Вт | 275 Вт | 250 Вт |
| SLI/CrossFire | - | CrossFire | SLI |
NVIDIA удалось еще сильнее увеличить эффективность. С одной стороны, тому способствовал 16-нм техпроцесс FinFET. С другой стороны, изменения в архитектуре SM тоже дали положительный эффект. NVIDIA для Tesla P100 указывает максимальное энергопотребление 300 Вт.
Не менее впечатляют тактовые частоты GPU GP100 у Tesla P100. NVIDIA выставила базовую частоту 1.328 МГц, в режиме Boost она увеличивается, как минимум, до 1.480 МГц. Подобные тактовые частоты стали возможными благодаря переходу на меньший техпроцесс. В любом случае, для карты вычислительных ускорений Tesla частота GPU 1.480 МГц впечатляет.
Позвольте более подробно рассмотреть структуру потоковых мультипроцессоров. Мы уже отметили 64 потоковых процессора на SM. Они относятся к категории FP32. У Maxwell и Kepler использовалось 128 или 192 потоковых процессора FP32 на SM, что указывает на явную ориентацию на одиночную точность. Каждый SM у GPU GP100 разделен на два блока. Каждый блок опирается на 32 потоковых процессора, буфер инструкций, Warp Scheduler и два диспетчера. Получается, что SM в архитектуре Pascal содержат в два раза меньше потоковых процессоров по сравнению с Maxwell, но размер регистров, warp и thread block не изменился.


Диаграмма GPU GP100 и SM
Количество блоков SM существенно увеличилось, то же самое касается памяти регистров. NVIDIA оптимизировала пути прохождения данных на кристалле. Конечно, NVIDIA удалось уменьшить площадь кристалла, что снизило энергопотребление и повысило эффективность. Также новая архитектура диспетчеров позволяет лучше нагружать конвейеры, любой Warp Scheduler может работать с двумя инструкциями Warp за такт.
Более высокая производительность с двойной точностью
Одним из фокусов при разработке архитектуры Pascal, на которую ушло три года и было затрачено 2-3 млрд. долларов США, является увеличение производительности вычислений с двойной точностью, а также рост производительности в приложениях, ориентированных на сети глубокого обучения (Deep Learning).
| Сравнение вычислительной производительности GPU-ускорителей | |||||
|---|---|---|---|---|---|
| Модель | NVIDIA Tesla P100 | NVIDIA Tesla K80 | NVIDIA Tesla M40 | AMD FirePro S9300 X2 | AMD FirePro S9150 |
| GPU | GP100 | 2x GK210 | GM200 | 2x Fiji | Hawaii |
| FP64 | 5,3 TFLOPS | 2,91 TFLOPS | 214 GFLOPS | 800 GFLOPS | 2,53 TFLOPS |
| FP32 | 10,6 TFLOPS | 8,74 TFLOPS | 6,844 TFLOPS | 13,9 TFLOPS | 5,07 TFLOPS |
| FP16 | 21,2 TFLOPS | - | - | - | - |
| Соотношение FP64/FP32 | 1/2 | 1/3 | 1/32 | 1/16 | 1/2 |
| Тип памяти | HBM2 | GDDR5 | GDDR5 | GDDR5 | GDDR5 |
| Объем памяти | 16 GB | 2x 12 GB | 12 GB | 2x 4 GB | 16 GB |
| Ширина шины памяти | 4.096 бит | 384 бит | 384 бит | 2x 4.096 бит | 512 бит |
| Пропускная способность памяти | 720 Гбайт/с | 2x 240 Гбайт/с | 288 Гбайт/с | 2x 512 Гбайт/с | 320 Гбайт/с |
| Потоковые процессоры | 3.840 | 4.992 | 3.072 | 8.192 | 2.816 |
Для существенного увеличения производительности с двойной точностью NVIDIA изменила соотношение вычислительных блоков FP64 и FP32. У архитектуры Kepler оно составляло 1/3, у предыдущей архитектуры Maxwell 1/32, теперь же NVIDIA обеспечивает соотношение 1/2 в архитектуре Pascal.
Для сетей глубокого обучения (Deep Learning) важны вычисления с половинной точностью или FP16, и здесь NVIDIA также обеспечивает соотношение 1/2 к вычислениям FP32. NVIDIA изменила обработку вычислений FP16 таким образом, чтобы задействовать выделенные ядра FP32. Некоторые вычисления FP16 можно объединять, что позволяет выполнять их на ядрах FP32. Однако для объединения вычислений FP16 они должны выполнять одинаковые операции. Например, можно объединять только две операции сложения или умножения. Операции FP16 важны для игр и расчетов текстур, для анализа данных фото и видео.
HBM2
Архитектура Pascal получила ряд оптимизаций, связанных с использованием памяти HBM2. Они касаются не только ширины интерфейса памяти, которая теперь составляет 4.096 битов, но и работы с атомными операциями. То есть с операциями записи и чтения в память. NVIDIA оптимизировала работу с атомными операциями в архитектуре Kepler, с Maxwell NVIDIA добавила «родную» поддержку Shared Memory Atomic Operations для 32-битных целых чисел и для 32- и 64-битных операций Compare-and-Swap (CAS). С GP100 NVIDIA теперь добавила атомное сложение FP64. В предыдущих архитектурах данную операцию приходилось делать через цикл Compare-and-Swap, что выполнялось медленнее «родной» поддержки.


Модуль Tesla P100 спереди и сзади
Память HBM2 производится Samsung. NVIDIA использует четыре чипа HBM2 емкость 4 Гбайт. Они состоят из четырех слоев, при этом используется более 5.000 сквозных соединений TSV (Through Silicon Vias). Подложка соединяет чипы памяти и GPU. Мы уже детально обсуждали технологию подложки в отдельной статье. Полный набор из GPU, памяти HBM2 подложки заключается в упаковку BGA 55 x 55 мм.
Чипы памяти NVIDIA подключены по 4.096-битному интерфейсу (4x 1.024 бит). Общая емкость составляет 16 Гбайт, поддерживается коррекция ошибок ECC, которая интегрирована в стандарт памяти. Поэтому активация ECC не приведет к уменьшению емкости или падению производительности. NVIDIA указывает пропускную способность 720 Гбайт/с, поэтому тактовая частота чипов HBM2 составляет около 740 МГц.
NVLink
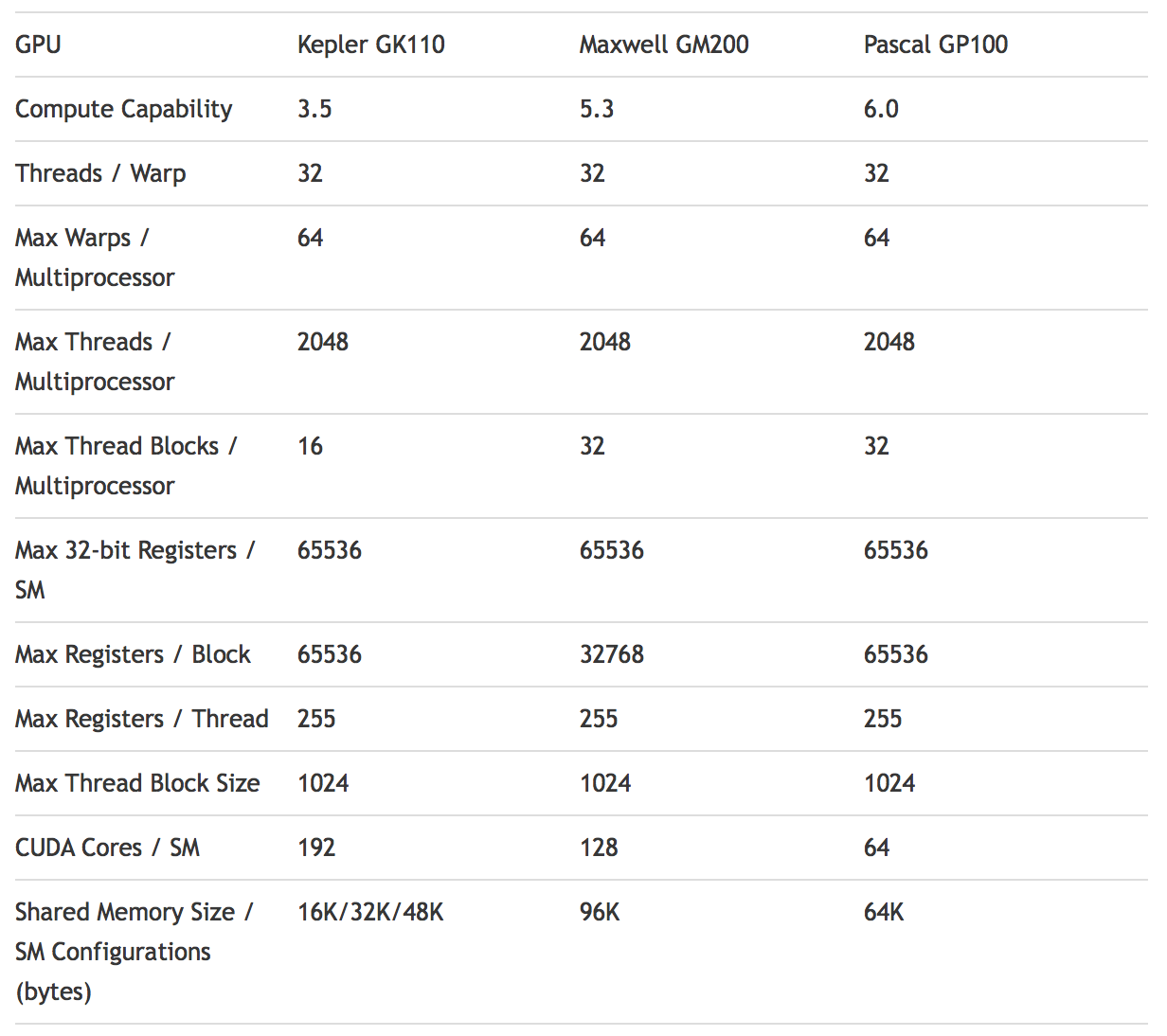
Кроме самого GPU и памяти HBM2 третьей важной функцией GP100 или архитектуры Pascal можно назвать поддержку NVLink. Впрочем, как раз для потребительского сегмента NVLink не так и важна. В любом случае, технология NVLink присутствует и привлекает внимание пользователей. NVLink призвана существенно увеличить скорость связи между GPU. 16 линий PCI Express 3.0 дают пропускную способность 15,75 Гбайт/с или 128 GT/s. Intel для своих ускорителей Knights Landing Xeon Phi реализовала Omni Path Interconnect, что тоже подчеркивает интерес процессорного гиганта к скоростным интерфейсам. NVLink также позволяет использовать унифицированную память на всех соединенных GPU с памятью. То есть Tesla P100 может обращаться к данным, располагающимся в памяти другого Tesla P100.
NVLink опирается на новый протокол NVHS (High-speed Interconnect Signaling). NVHS обеспечивает пропускную способность 20 Гбит/с на линию благодаря дифференциальной схеме кодирования сигналов. Восемь линий обеспечивают субканал. Два субканала дают канал, который может соединять, например, два GPU (GPU-to-GPU или GPU-to-CPU). Пропускная способность канала составляет 40 Гбайт/с в двух направлениях, причем эффективная скорость составляет 97% от указанной пропускной способности. Так что избыточной информации передается очень немного.
GPU GP100 поддерживает четыре канала. Причем они тоже могут объединяться. В случае GPU GP100 максимальная пропускная способность подключения может составлять до 160 Гбайт/с. Можно использовать две пары каналов по 80 Гбайт/с каждая. Конкретная структура NVLink в сервере зависит от реализации и сценариев использования.
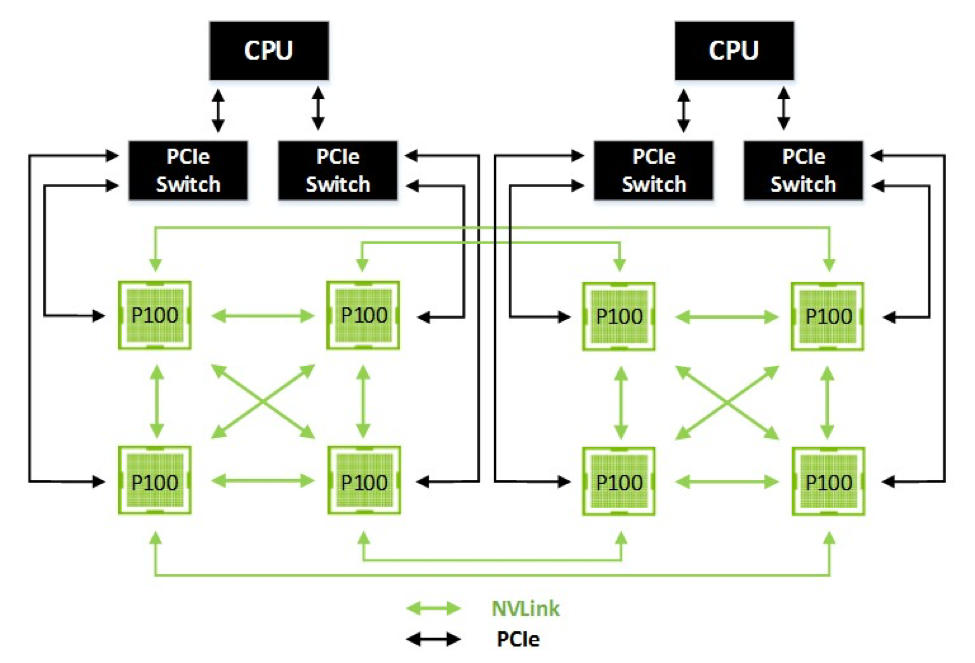
В качестве примера можно привести сочетание восьми GPU GP100 на вычислительном модуле Tesla P100. На модуле Tesla P100 видны две пары из четырех GPU, внутри четверки каждый GPU соединяется с каждым, а также с одним GPU из другой четверки. Связь с двумя CPU обеспечивается интерфейсами PCI Express.
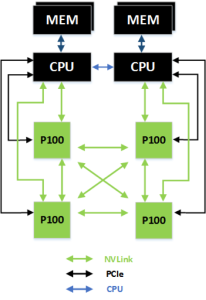
IBM стала первым производителем, интегрировавшим поддержку NVLink в свои CPU. Поэтому скоро можно ожидать появление серверов с ускорителями Tesla P100, которые будут использовать для связи NVLink – в данном случае это касается и связи с CPU.
Unified Memory
Унифицированная память (Unified Memory) – не новая функция GPU, но NVIDIA внесла дальнейшие оптимизации в архитектуре Pascal, теперь реализация унифицированной память стала еще шире. Unified Memory была представлена вместе с CUDA 6, но в архитектурах Kepler и Maxwell оставался ряд ограничений. CPU не мог обращаться к памяти GPU без предварительной синхронизации последней. Одновременный доступ к выбранной части памяти был невозможен. Также и размер унифицированной памяти был ограничен видеопамятью.
С Pascal или CUDA 8 NVIDIA представляет новую виртуальную память с 49-битным адресным пространством. Оно достаточно велико, чтобы включить в себя всю память CPU и GPU в системе. Унифицированная память больше не ограничивается по объему видеопамятью. NVIDIA говорит о максимальном объеме унифицированной памяти 192 Тбайт.
Помимо увеличения объема, унифицированная память в нынешней реализации получила ряд функций, упрощающих работу с ней. Одна из новых функций - Page Faulting. GPU и CPU могут независимо работать с областями памяти без предварительной синхронизации. На когерентность памяти это не повлияет, она в каждом случае гарантируется. Но разработчикам следует быть осторожным, чтобы в случае Page Faulting не потерять данные, которые нужны другим CPU и GPU. В таких случаях все равно необходимо выполнять синхронизацию, чтобы предотвратить потерю данных.
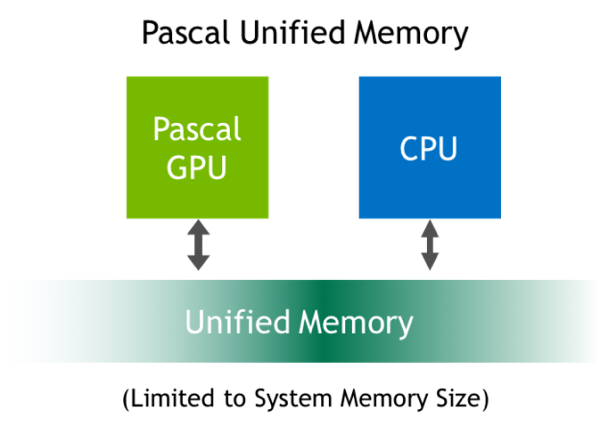
Некоторые операционные системы могут использовать унифицированную память как собственную штатную память. В таких случаях можно пользоваться стандартными процедурами Malloc или New. В указателях ничего менять тоже не нужно, унифицированная память полностью доступна для операционной системы. В результате массив памяти может быть очень большим, поскольку он будет включать память CPU и GPU в системе. Такой подход позволит обрабатывать большие массивы данных.
Мы постарались привести все подробности архитектуры Pascal и первой карты Tesla P100 на данном GPU. Если верить информации NVIDIA, карты уже выпускаются и поставляются клиентам. Возникает вопрос: когда нам ждать видеокарт GeForce на GPU GP100? Судя по всему, здесь ограничивающим фактором является HBM2. Возможно, первыми появятся «младшие» GPU на архитектуре Pascal, которые могут использовать поначалу GDDR5 или GDDR5X. Деталей о подобных продуктах на GPU Technology Conference NVIDIA не привела, к сожалению.