

 В Интернете пользователи повсеместно сталкиваются с результатами работы сетей глубокого обучения, хотя часто об этом и не подозревают. Под глубоким обучением (Deep Learning) понимают различные сервисы, в той или иной мере использующие искусственный интеллект. Хотя они связаны не столько с искусственным интеллектом, сколько с анализом данных. В любом случае, сети глубокого обучения будут использоваться в будущем повсеместно, поэтому многие компании спешат представить соответствующее аппаратное оснащение.
В Интернете пользователи повсеместно сталкиваются с результатами работы сетей глубокого обучения, хотя часто об этом и не подозревают. Под глубоким обучением (Deep Learning) понимают различные сервисы, в той или иной мере использующие искусственный интеллект. Хотя они связаны не столько с искусственным интеллектом, сколько с анализом данных. В любом случае, сети глубокого обучения будут использоваться в будущем повсеместно, поэтому многие компании спешат представить соответствующее аппаратное оснащение.
Intel позиционирует на данную сферу свои GPU-ускорители Xeon Phi, а та же Google разработала собственные чипы TPU. Одним из пионеров глубокого обучения можно назвать и NVIDIA. Вычислительную производительность современных GPU можно использовать не только для отрисовки треугольников и наложения текстур, но и для выполнения большого числа параллельных вычислительных задач – как раз такая нагрузка и характерна для сетей глубокого обучения.

Нагрузку сетей глубокого обучения на аппаратные ресурсы можно разделить на две части. Сначала выполняется этап тренировки. Например, сеть анализирует несколько миллиардов фотографий в нужных категориях. Что изображено на снимке? Есть ли там птица, чем она занимается и к какому виду относится? В результате создаются сложные базы данных с несколькими миллиардами узлов. Для тренировки сети глубокого обучения требуется огромная вычислительная производительность, чтобы процесс занимал не месяцы или дни, а несколько часов. Для подобного процесса NVIDIA и разработала серверы DGX-1. Каждый стоечный сервер использует восемь Tesla P100 на архитектуре Pascal. Каждый чип оснащен 3.584 потоковыми процессорами, 16 Гбайт памяти HBM2 с пропускной способностью 720 Гбайт/с, что позволяет P100 справляться с подобными вычислительными задачами.


NVIDIA Tesla P4 и Tesla P40
Tesla P4 и P40 ускоряют поиск информации в сетях глубокого обучения
Выше мы описывали первую часть нагрузки – тренировку. Вторая часть связана с обработкой запросов в наполненную информацией сеть глубокого обучения (инференс). Здесь требуется получать результат как можно быстрее, что достигается большим количеством параллельных вычислений. И как раз для такой нагрузки NVIDIA и представила сегодня GPU-ускорители Tesla P4 и P40.
Запрос в сеть глубокого обучения должен обрабатываться даже не секунды, а считанные доли секунды. По крайней мере, такую цель поставила перед собой NVIDIA. Низкие задержки важны при прямом обращении пользователя в сеть. Из примеров можно привести голосовой запрос на поиск близлежащего ресторана, когда сеть глубокого обучения распознает голос, после чего проведет поиск ресторана. Вряд ли пользователю будет комфортно ждать ответ на свой запрос на протяжении нескольких секунд. Ответ должен прийти как можно быстрее.


NVIDIA Tesla P4 и Tesla P40
Но перейдем к аппаратному обеспечению. начнем с Tesla P4. Вычислительный ускоритель довольно компактный, он фокусируется на сферы использования, где важна не только скорость, но и эффективность. Tesla P4 базируется на том же GP104, что и игровая видеокарта GeForce GTX 1080, но ускоритель более компактный. Чтобы уменьшить систему охлаждения, NVIDIA выставила для 2.560 потоковых процессоров очень низкие частоты. NVIDIA для выставления частоты и производительности использует два режима. В первом P4 Base (определен как SGEMM) ускоритель Tesla P4 достигает частоты GPU 810 МГц, эквивалентной вычислительной производительности 16,6 TOPS (INT8). Вычислительная производительность с одинарной точностью достигает 4,15 TFLOPS. В режиме P4 Boost (определен как 70% SGEMM) ускоритель Tesla P4 достигает частоты Boost 1.063 МГц, что соответствует 21.8 TOPS (INT8). Производительность с одинарной точностью достигает в этом случае 5,5 TFLOPS. 8 Гбайт памяти GDDR5 работают с пропускной способностью 192 Гбайт/с. Энергопотребление, в зависимости от режима, составляет 50 или 75 Вт. Для GPU GP104 уровень 50/75 Вт действительно очень небольшой, что еще раз подчеркивает эффективность архитектуры Pascal от NVIDIA.
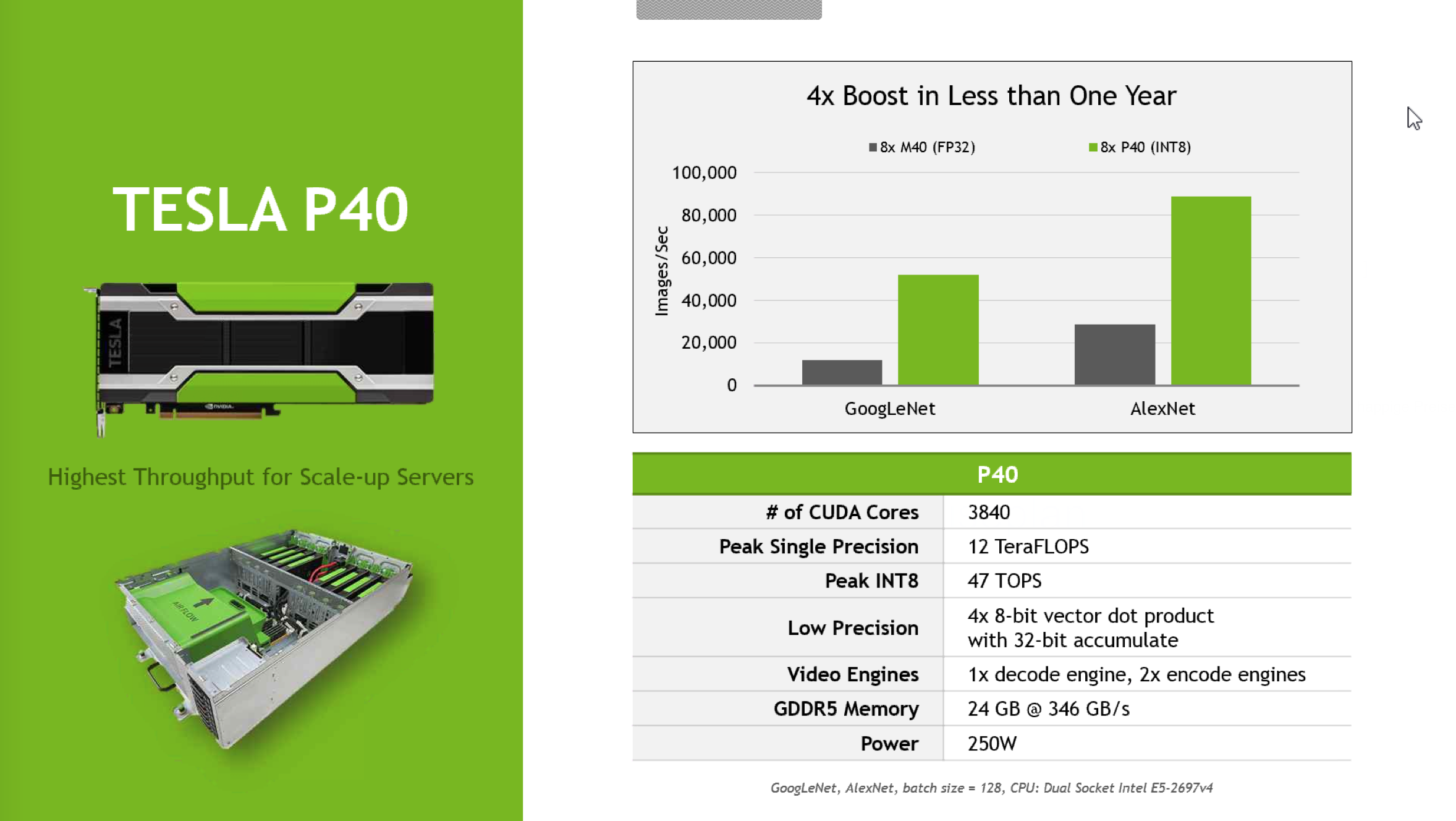
Вторая новая вычислительная карта - Tesla P40. Она использует уже GPU GP102, который мы встречали в тех же Titan X или Quadro P6000. Для Tesla P40 NVIDIA указывает уже значительно более высокий тепловой пакет 250 Вт, так что вычислительный ускоритель интересен для тех окружений, где на первом месте стоит производительность, а не эффективность. У Tesla P40 мы получаем тоже два режима тактовой частоты. Базовая частота составляет 1.303 МГц, что соответствует 40 TOPS (IN8) или 10 TFLOPS с одинарной точностью. В режиме Boost частота увеличивается до 1.531 МГц, карта ускоряется до 47 TOPS (INT8) или 12 TFLOPS. 24 Гбайт памяти работают с пропускной способностью 346 Гбайт/с.
NVIDIA Tesla P4 и Tesla P40
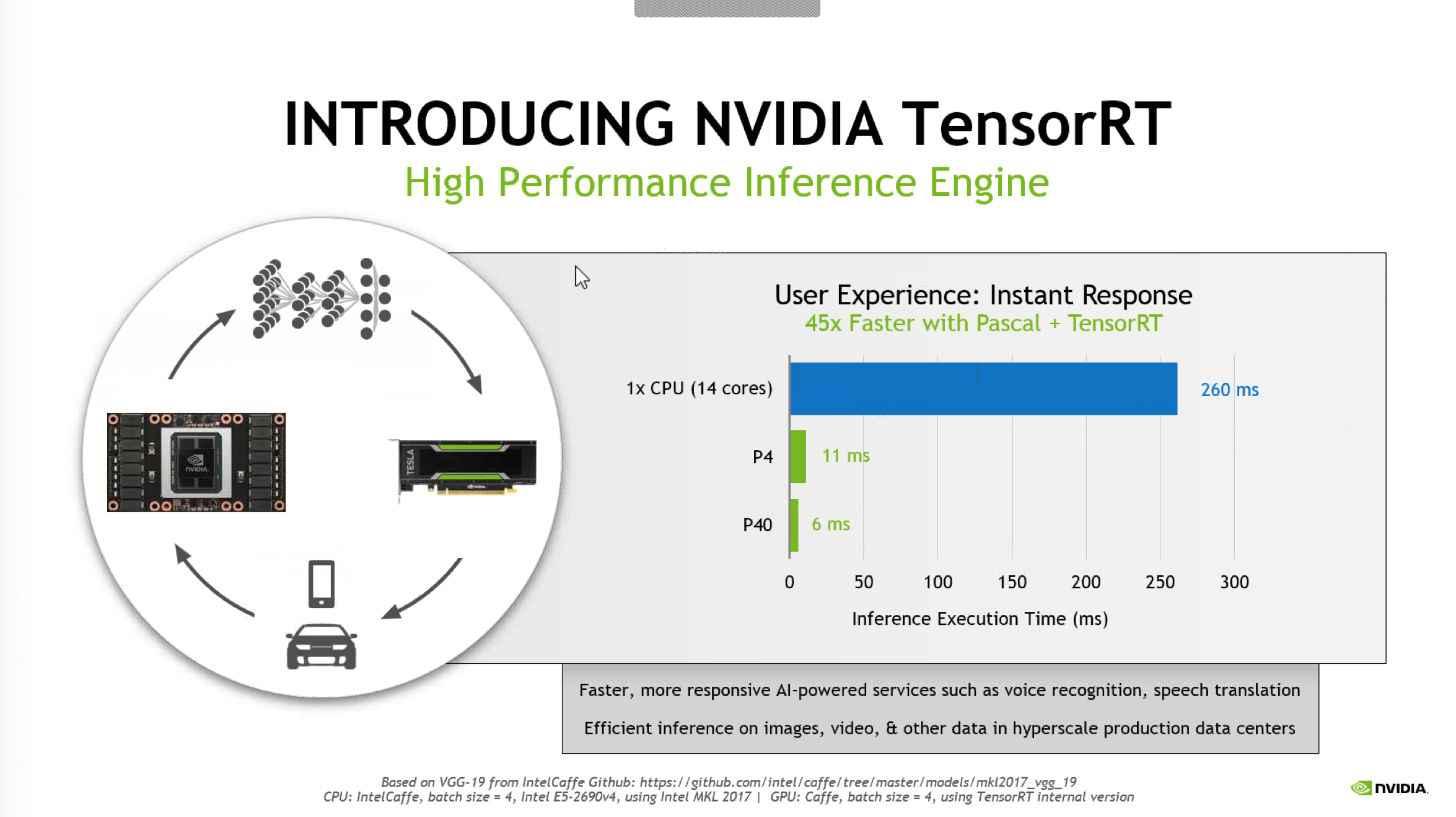
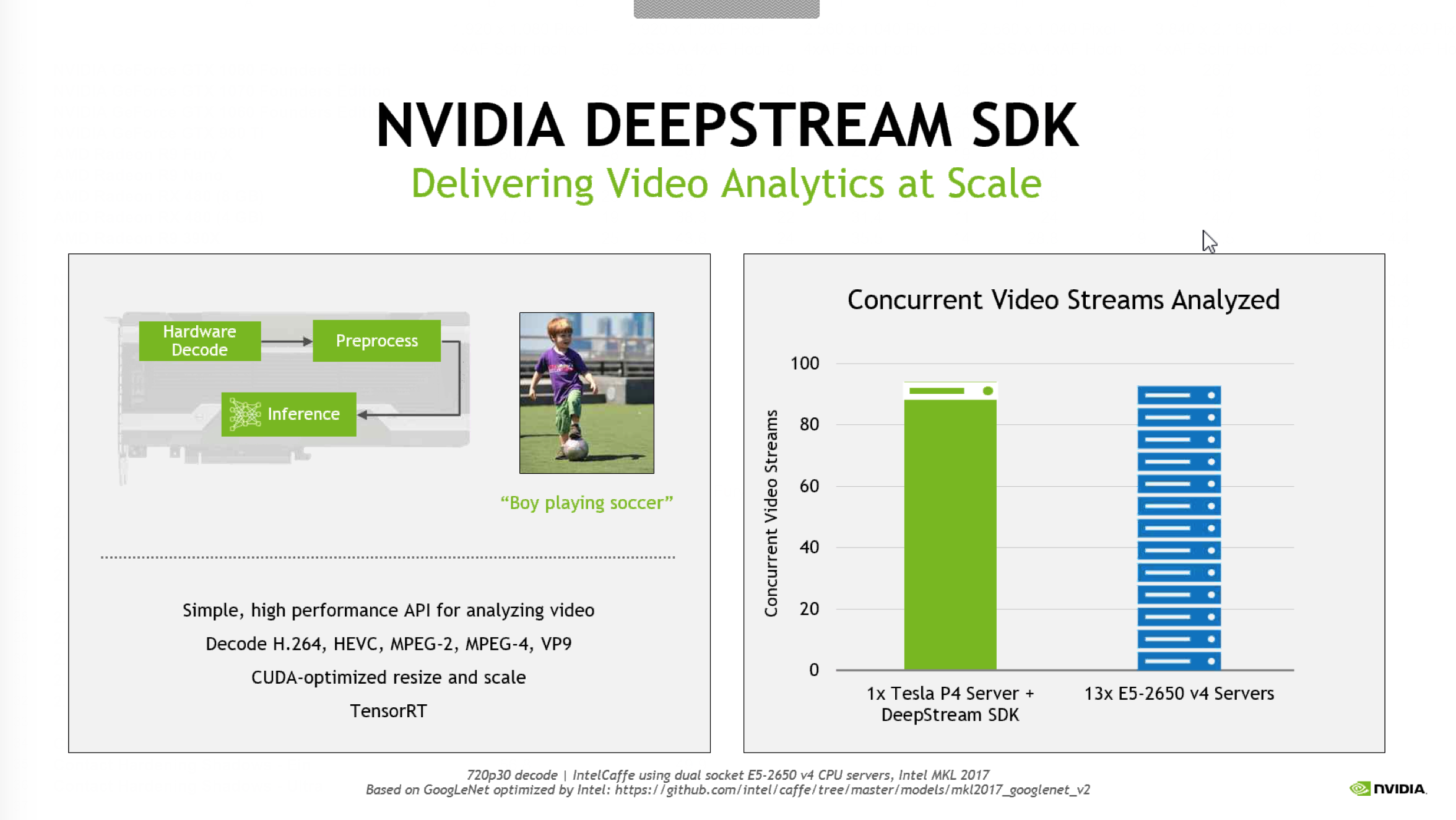
NVIDIA также предоставила результаты производительности ускорителей в сетях глубокого обучения. Если на CPU Intel с 14 ядрами задержка составляет 260 мс, в случае Tesla P4 она снижается до всего 11 мм, а с ускорителями Tesla P40 – до 6 мс. NVIDIA в качестве примера приводит работу сетей глубокого обучения с потоками видео, здесь тоже приводятся результаты производительности. Сервер с Tesla P4, например, анализирует чуть больше 90 потоков (720p на 30 FPS) одновременно, для такой же задачи требуются 13 серверов на Intel Xeon E5-2650. Впрочем, сложно сказать, насколько точно данные тесты соответствуют реальности.
NVIDIA работает с несколькими производителями серверов, соответствующие системы с Tesla P40 будут доступны с октября, а серверы на Tesla P4 появятся только в ноябре. Цену NVIDIA пока не указывает.


NVIDIA Tesla P4 и Tesla P40
С представлением ускорителей Tesla P4 и P40 NVIDIA закрывает полный цикл задач глубокого обучения. Все это должно привести к значительному росту производительности Deep Learning.