

 На конференции HotChips Microsoft представила системную архитектуру Xbox Series X. Мы уже знаем почти все технические спецификации специализированной SoC, которая разрабатывалась вместе с AMD. Конечно, интерес здесь, в первую очередь, вызывает архитектура встроенного GPU, поскольку восемь ядер Zen 2 нам знакомы по настольному и мобильному сегментам.
На конференции HotChips Microsoft представила системную архитектуру Xbox Series X. Мы уже знаем почти все технические спецификации специализированной SoC, которая разрабатывалась вместе с AMD. Конечно, интерес здесь, в первую очередь, вызывает архитектура встроенного GPU, поскольку восемь ядер Zen 2 нам знакомы по настольному и мобильному сегментам.
Встроенный GPU поддерживает Sampler Feedback Streaming (SFS), Variable Rate Shading (VRS), D3D Mesh Shading и, что особенно интересно, Machine Learning Acceleration и DirectX Raytracing (DXR). Все эти функции ожидаются и от будущих видеокарт Radeon на основе архитектуры RNDA 2 для настольных систем. Так что Microsoft здесь приоткрывает завесу тайны над новыми видеокартами AMD, которые появятся не раньше осени.
Встроенный в Xbox Series X GPU поддерживает 26 сдвоенных блоков Dual CU (Compute Unit) по 128 потоковых процессоров в каждом. В принципе, они знакомы по первому поколению архитектуры RDNA. В общей сложности мы получаем 3.328 потоковых процессоров, Microsoft и AMD не активируют два блока Dual CU, чтобы не снижать долю выхода годных кристаллов.








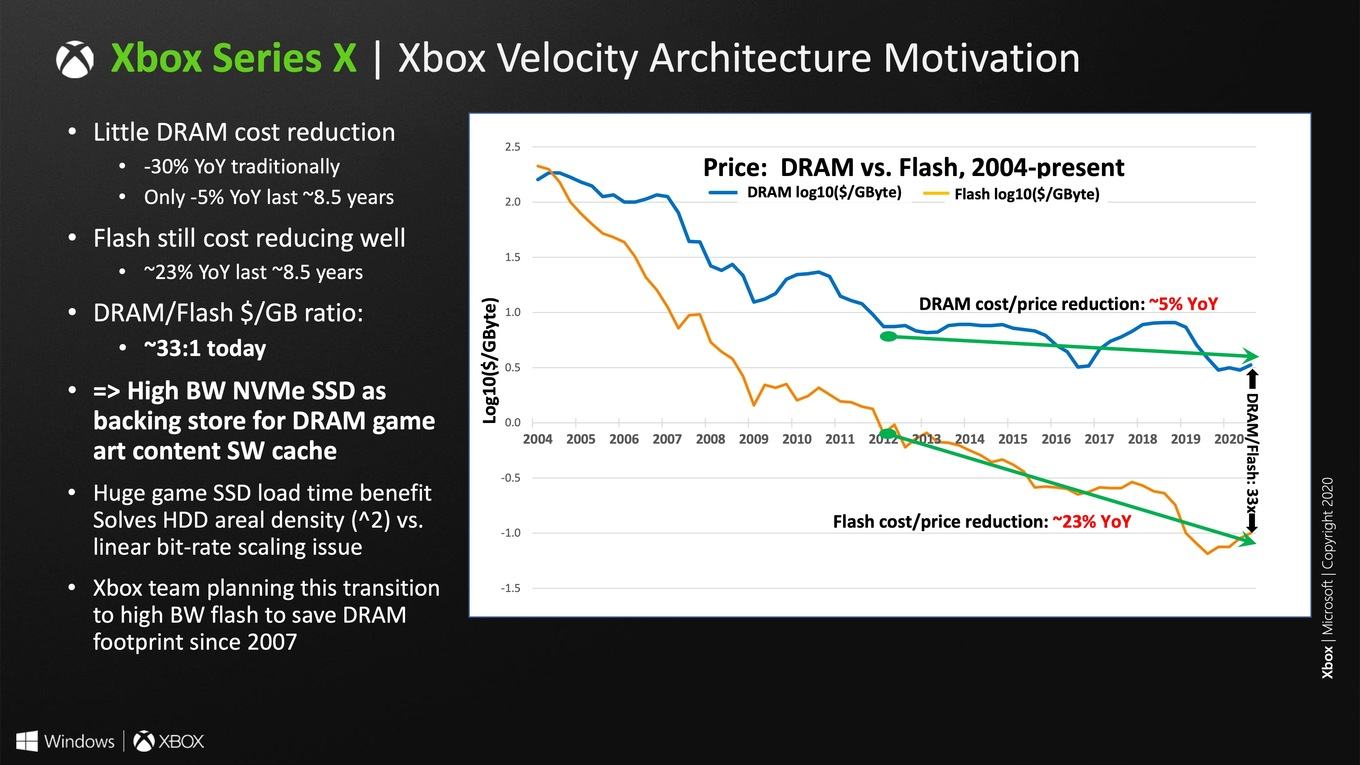





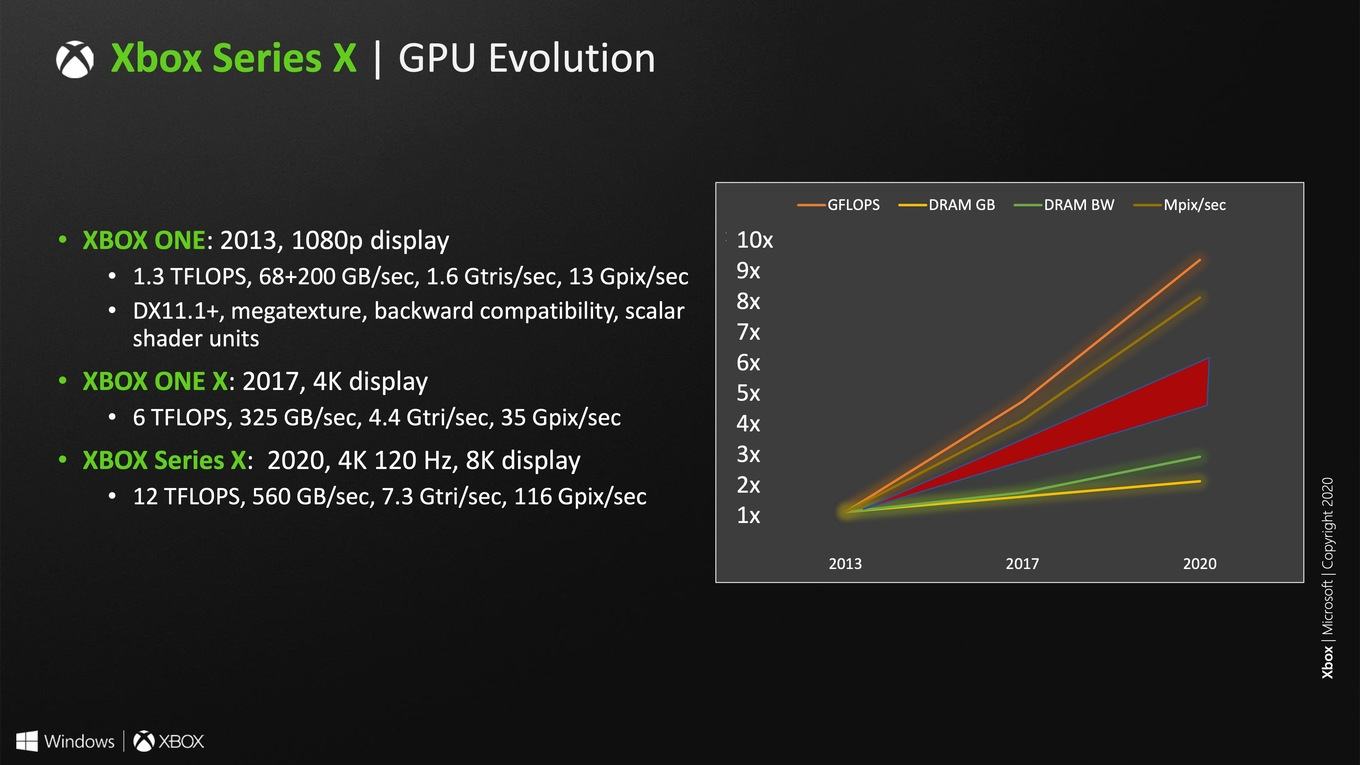
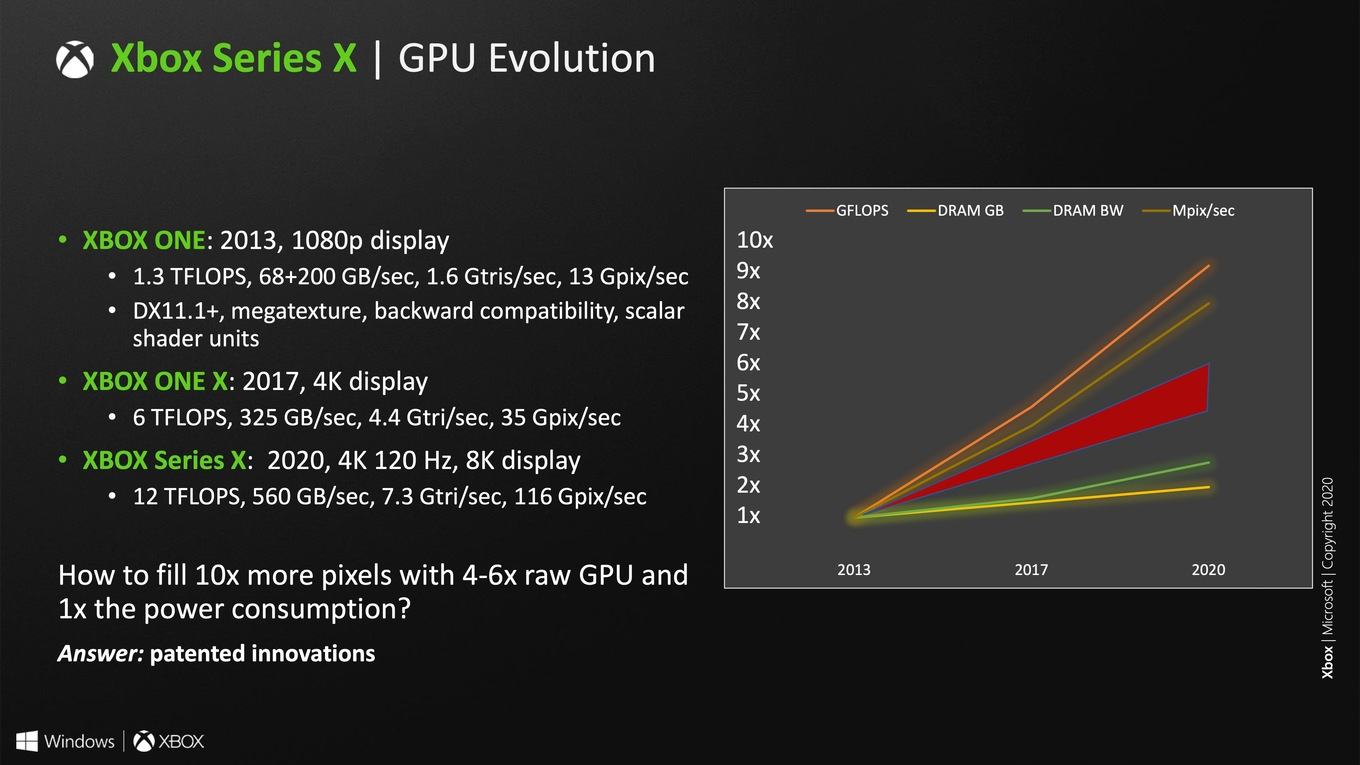













Если присмотреться к опубликованным диаграммам, то большое количество важной информации пока отсутствует. AMD, вероятно, приберегла подробности к дате публикации архитектуры RDNA 2. Но какие-то сведения получить можно, например, 5 Мбайт кэша L2. Но объем кэша может измениться при переходе с GPU специализированных чипов Xbox Series X к Big Navi, поскольку он зависит от того, сколько места остается непосредственно на чипе. Для настольных чипов данная проблема стоит не так остро, как для специализированных SoC или мобильных GPU.
Как видно по структуре сдвоенного CU, имеется не меньше четырех ускорителей трассировки лучей и не меньше четырех текстурных блоков на CU. Microsoft не дает конкретное число текстурных блоков и ускорителей трассировки лучей, но для архитектуры RDNA их число составляло четыре. Что касается ускорителей трассировки лучей, то их точная структура остается неизвестной, как и число текстурных блоков. Но слайды указывают на четыре операции трассировки лучей или текстурных операций за такт. Что позволяет предположить четыре блока ускорения трассировки лучей. 2x 32 SIMD32 дает 64 потоковых процессора на CU, то есть 128 на Dual CU.
Также в Dual CU есть общий кэш Local Data Share (LDS), кэши Scalar Data Cache и Shader Instruction Cache. Сходства между архитектурами RDNA и RDNA 2 видны с первого взгляда. Вероятно, AMD добавит ускорители трассировки лучей к блокам Compute Units, также можно рассчитывать и на некоторые дополнительные функции CU.
На тактовой частоте 1.825 МГц 3.328 потоковых процессора Xbox Series X GPU обеспечивают вычислительную производительность 12 TFLOPS. У Radeon RX 5700 XT мы получаем 9,4 TFLOPS. Но важнее то, что GPU работает более эффективно, в том числе благодаря технологиям Variable Rate Shading (VRS) и Sampler Feedback Streaming.
Технологию VRS мы уже рассматривали несколько раз, поскольку она поддерживается (и используется) NVIDIA. Sampler Feedback Streaming - новая технология, которую будет поддерживать и NVIDIA вместе с DirectX 12 Ultimate. Sampler Feedback Streaming может использоваться для улучшения скорости загрузки/стриминга текстур, повышая эффективность графической подсистемы без необходимости повторного полного наложения текстур. Более детальные текстуры и более крупные игровые миры приводят к увеличению времени загрузки. Стриминг текстур призван загружать только те текстуры в память видеокарты, которые действительно потребуются. С помощью обратной отдачи (feedback map) семплер получит необходимую информацию о нужных текстурах.
Благодаря обратной отдаче (Sampler Feedback) можно выполнить затенение в пространстве текстуры (Texture Space Shading). При этом различные вычисления шейдеров не придется выполнять заново, результаты можно повторно использовать несколько раз, что поднимает производительность GPU.
Пару слов о производительности трассировки лучей. В архитектуре Turing NVIDIA использует по одному ядру RT на блок SM для аппаратного ускорения трассировки лучей. И AMD, по всей видимости, использует четыре блока ускорения трассировки лучей на CU. Спецификации производительности несколько запутывают, поскольку AMD указывает "380G/sec ray-box peak" и "95G/sec ray-tri peak". AMD, похоже, использует потоковые процессоры для вычислений Bounding Volume Hierarchy (BVH).
Microsoft указывает небольшую площадь чипа, которые занимают ускорители трассировки лучей, по отношению к приросту производительности - от 3 до 10 раз. То же самое касается и ускорения алгоритмов ИИ, отвечающих за масштабирование разрешений. Вероятно, AMD планирует ответить на NVIDIA DLSS?
В любом случае, нужно дождаться подробностей архитектуры RDNA 2. Информация о SoC приставки Xbox Series X дает лишь скудные сведения. Чипы Big Navi наверняка будут оптимизированы для работы на high-end сегменте. Но существенных отличий по архитектуре мы не ожидаем.
Подписывайтесь на группы Hardwareluxx ВКонтакте и Facebook, а также на наш канал в Telegram (@hardwareluxxrussia).
Мы рекомендуем ознакомиться с нашим руководством по выбору видеокарты для разных бюджетов.