

 Как и предполагалось, на пленарном докладе конференции GTC 2022 NVIDIA представила преемницу архитектуры Ampere под названием Hopper. Первый GPU GH100 на новой архитектуре ориентирован на дата-центры, как и предшественник GA100 GPU. Кристалл GH100 GPU производится по 4-нм техпроцессу на мощностях TSMC (N4), NVIDIA указывает число транзисторов 80 млрд. У предшественника их число составляло 54 млрд., а производился он по 7-нм техпроцессу.
Как и предполагалось, на пленарном докладе конференции GTC 2022 NVIDIA представила преемницу архитектуры Ampere под названием Hopper. Первый GPU GH100 на новой архитектуре ориентирован на дата-центры, как и предшественник GA100 GPU. Кристалл GH100 GPU производится по 4-нм техпроцессу на мощностях TSMC (N4), NVIDIA указывает число транзисторов 80 млрд. У предшественника их число составляло 54 млрд., а производился он по 7-нм техпроцессу.
Архитектура Hopper названа в честь американского ученого, математика и программиста Грейс Хоппер. NVIDIA продолжает добрую традицию именования своих архитектур в честь знаменитых ученых. GPU назван GH100, а соответствующий продукт - H100.
GH100 - первый GPU-ускоритель с поддержкой PCI Express 5.0 и шестью чипами памяти HBM3 с пропускной способностью 3 Тбайт/с и емкостью 80 Гбайт. Но NVIDIA, похоже, использует только пять чипов памяти из установленных шести, такой же принцип мы видели и у предшественника GA100 GPU. В чем причина - неизвестно. Скорее всего, NVIDIA перестраховывается на случай низкой доли выхода годных кристаллов и дефектов.
GH100 GPU в модуле SMX работает с тепловым пакетом до 600 Вт. Данный уровень был ожидаем, у предшественника уже было 500 Вт. И тенденция в направлении 500 Вт и выше среди GPU-ускорителей прослеживается довольно давно.

Центральным компонентом GH100 GPU являются вычислительные блоки. А именно 18.432 вычислительных блока FP32, которые дополняют 9.216 блока INT32 и столько же блоков FP64 вместе с ядрами Tensor четвертого поколения. NVIDIA теперь добавляет программный слой Transformer Engine, который позволяет более эффективно загрузить ядра Tensor. Последние ориентированы на вычисления с точностью 16 и 8 битов. В случае двойной точности FP64 GPU H100 дает производительность 60 TFLOPS.
| H100 | A100 | Instinct MI250X | |
| Техпроцесс | 4 нм | 7 нм | 6 нм |
| Количество транзисторов | 80 млрд. | 54 млрд. | 58 млрд. |
| Производительность FP64 (TFLOPS) | 60 | 19,5 | 47,9 |
| FP32/Производительность TF32 (TFLOPS) | 1.000 | 156 | 47,9 |
| Производительность FP16 (TFLOPS) | 2.000 | 624 | 383 |
| Производительность FP8 (TFLOPS) | 4.000 | - | - |
| Память | 80 GB HBM3 3 Тбайт/с | 80 GB HBM2 2 Тбайт/с | 128 GB HBM2E 3,2 Тбайт/с |
| PCIe | 5.0 | 4.0 | 4.0 |
| Интерконнект | NVLink 900 Гбайт/с | NVLink | Infinity Link 800 Гбайт/с |
| TDP | 600 Вт | 500 Вт | 560 Вт |
Начнем с того, что NVIDIA использует техпроцесс TSMC N4 для GH100 GPU, предшественник изготавливался по техпроцессу N7. AMD производит оба чиплета ускорителя Instinct MI250X по технологии 6 нм, тоже на TSMC. Сложность GH100 GPU становится очевидной, если посмотреть на число транзисторов. Их число увеличилось до 80 млрд. против 54 млрд. у предшественника GA100 GPU, а также 58 млрд. у двух кристаллов Instinct MI250X.
Как мы уже упоминали выше, GPU работает с 80 Гбайт памяти. Но переход с HBM2 на HBM3 позволил существенно увеличить ее пропускную способность. Впрочем, 128 Гбайт ускорителя Instinct MI250X остаются недостижимыми как по емкости, так и по пропускной способности.
Сравнивать вычислительную производительность довольно сложно. Для GA100 GPU NVIDIA приводит значения производительности потоковых процессоров и блоков Tensor с идеальной загрузкой. В таблице мы как раз указали данные максимальные значения. В случае нового ускорителя H100 мы не знаем точную структуру GPU, поэтому приходится использовать только информацию, полученную от NVIDIA.
Внешнее подключение обеспечивается через PCIe 5.0, но NVIDIA поддерживает четвертое поколение NVLink, позволяющее максимально быстро обмениваться данными между несколькими GPU. NVIDIA указывает, что пропускная способность NVLink в семь раз превышает таковую у PCIe 5.0, а именно 900 Гбайт/с на GH100 GPU. В результате суммарная пропускная способность внешних подключений GH100 GPU достигает почти 5 Тбайт/с. Новый NVLink играет важную роль и по взаимодействию с процессором Grace. Его мы рассмотрели в отдельной новости.
Transformer Engine и ядра Tensor 4-го поколения
С архитектурой Hopper NVIDIA вновь сфокусировалась на максимальной гибкости. Ускоритель H100 GPU должен справляться как с научными вычислениями с двойной точностью (FP64), так и с приложениями ИИ (INT8, FP8 и FP16) – при оптимальном расходовании доступных ресурсов.
По этой причине NVIDIA представила с архитектурой Hopper ядра Tensor четвертого поколения, которые сочетаются с программным слоем под названием Transformer Engine.
Ядра Tensor архитектуры Hopper могут выполнять вычисления Mixed FP8 и FP16. Причем в случае FP8 пропускная способность в два раза превышает FP16. Специальные алгоритмы эвристики NVIDIA определяют, какой формат предпочтительнее для вычислений, FP8 или FP16. Формат TensorFloat32 (TF32) остается в TensorFlow и PyTorch по умолчанию, затем эти вычисления преобразуются в FP8 и FP16 через Transformer Engine, чтобы оптимально задействовать вычислительные возможности ядер Tensor.
Конечно, описанные выше вычисления важнее всего для тренировки сетей глубокого обучения. Для инференса основное значение имеют вычисления INT8. Они на архитектуре Hopper тоже могут выполняться в оптимизированном виде, здесь ускорители H100 тоже будут работать существенно быстрее предшественников.
NVLink Switch System
NVLink теперь может использоваться не только для соединения восьми GH100 GPU в системе DGX-H100, но также и для соединения систем в стойках через NVLink Switch System. Через NVLink можно соединять до 256 H100 GPU.


Максимальная суммарная пропускная способность NVLink Switch System составляет 70,4 Тбайт/с. Для управления подобной сетью требуется вычислительная производительность, здесь NVIDIA указывает 192 TFLOPS. Для сравнения: новый Ethernet-коммутатор Spectrum-4 дает суммарно до 50,2 Тбит/с (6,275 Тбайт/с).
Кроме интеграции в GH100 GPU, а также Grace Hopper и Grace CPU Superchip, интерфейс NVLink может использоваться и в других чипах. Такой подход, как рассчитывает NVIDIA, облегчит подключение сторонних чипов к продуктам компании.
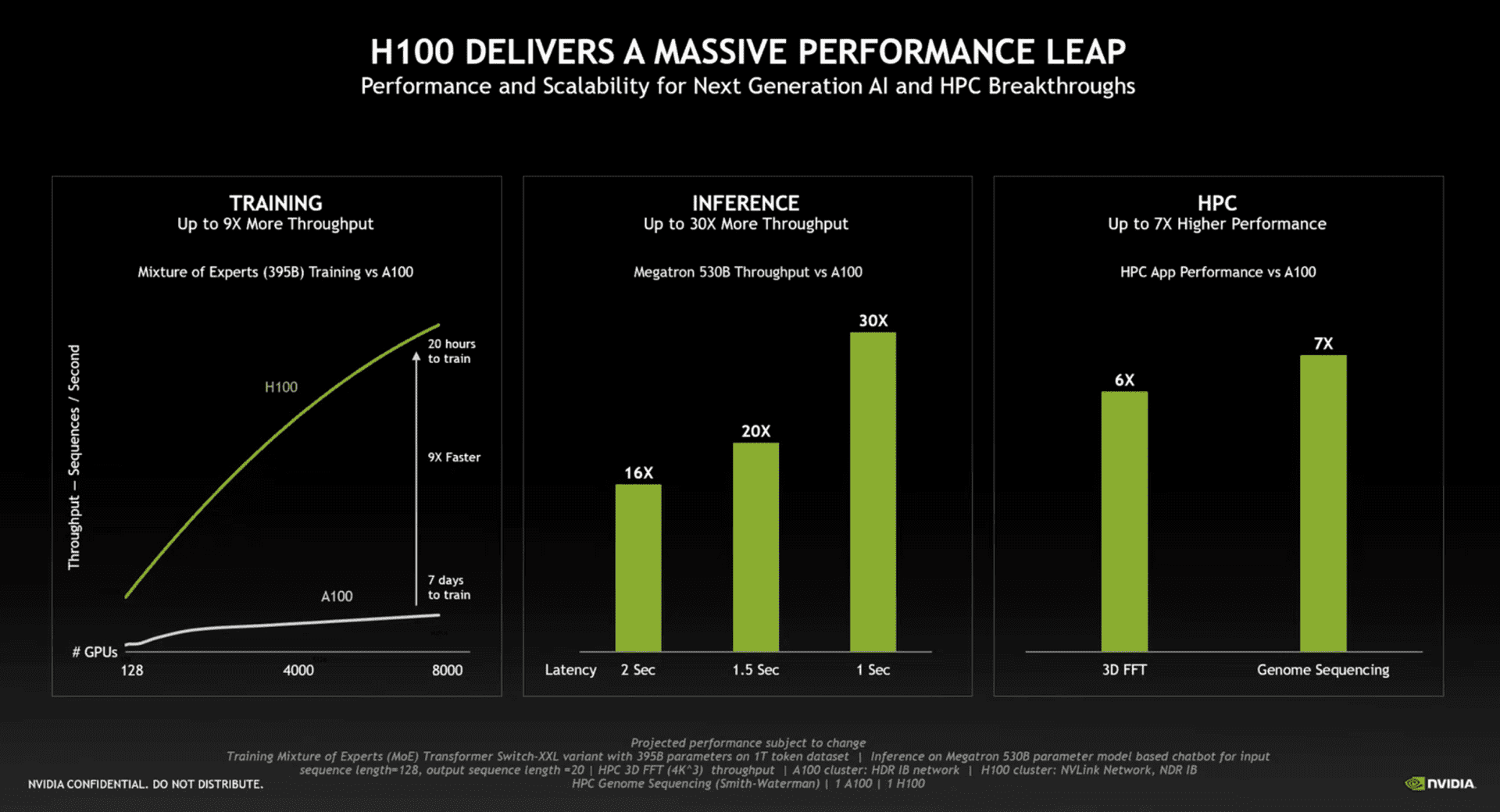
NVIDIA ожидает, что GPU-ускоритель H100 будет в девять раз быстрее предшественника. Хотя здесь все зависит от сценария. Скорее всего, NVIDIA подразумевает соответствующее снижение времени тренировки сетей глубокого обучения.
H100 GPU будет доступен на модулях SMX и картах расширения PCI Express. NVIDIA также планирует комбинировать H100 GPU на PCB с сетевым контроллером ConnectX-7. Подобные системы с быстрым подключением и высокой производительностью весьма полезны для периферийных вычислений.
NVIDIA планирует поставлять первые H100 GPU уже в третьем квартале. Производство кристаллов уже стартовало. NVIDIA собирается построить и собственный суперкомпьютер на GPU-ускорителях H100. Он будет содержать 576 систем DGX H100 с восемью H100 каждая.
Обновление:
После пленарного доклада NVIDIA поделилась некоторым подробностями полной версии чипа GH100, а также реализации конкретных продуктов в виде модуля SMX5 и карты расширения PCIe. Площадь чипа составляет 814 мм², он производится по 4-нм техпроцессу.
| GH100 (полная версия) | H100 SMX5 | H100 PCIe | |
| GPCs | 8 | 8 | 7 oder 8 |
| TPCs | 72 | 66 | 57 |
| SMs | 144 | 132 | 114 |
| Блоки FP32 | 18.432 | 16.896 | 14.592 |
| Кэш L2 | 60 MB | 50 MB | 50 MB |
| Ядра Tensor | 576 | 528 | 456 |
| Памятьr | 96 GB HBM3/HBM2E | 80 GB HBM3 | 80 GB HBM2E |
| TDP | - | 600 W | 350 W |
Полная версия GH100 GPU содержит 8 GPC, 72 TPC (9 TPC на GPC) и два SM на TPC. В результате чип предлагает 144 SM. Однако NVIDIA не стала выпускать чип в полной версии, ускоритель H100 получает примерно на 10% меньше функциональных блоков. Активны только 132 SM, то есть 16.896 потоковых процессоров. Число ядер Tensor (четыре на SM) и кэш L2 пропорционально урезаны. Из шести чипов памяти HBM3 или HBM2E активны только пять. TDP варианта PCI Express составляет 350 Вт.
Подписывайтесь на группы Hardwareluxx ВКонтакте и Facebook, а также на наш канал в Telegram (@hardwareluxxrussia).