

 Следуя шестимесячному циклу, MLCommons выпустила результаты тестов инференса обновленной версии MLPerf Inference 1.1. Как обычно, результаты были предоставлены Dell, HPE, Inspur, Intel, Lenovo, NVIDIA, Qualcomm, Gigabyte, Supermicro и другими вендорами. При этом участники могут верифицировать результаты конкурентов. Конечно, такая возможность есть и у MLCommons.
Следуя шестимесячному циклу, MLCommons выпустила результаты тестов инференса обновленной версии MLPerf Inference 1.1. Как обычно, результаты были предоставлены Dell, HPE, Inspur, Intel, Lenovo, NVIDIA, Qualcomm, Gigabyte, Supermicro и другими вендорами. При этом участники могут верифицировать результаты конкурентов. Конечно, такая возможность есть и у MLCommons.
Теперь доступны результаты теста инференса 1.1. Результаты разделены на дата-центры и периферийные (edge) серверы. В случае периферийных серверов акцентируется эффективность, для дата-центров важна масштабируемость обработки сложных массивов данных.
Тесты искусственного интеллекта и машинного обучения не такие простые, как запуск 3DMark, например. Для проведения серверных тестов нам уже приходится выполнять немало дополнительной работы. А тесты MLPerf еще сложнее. Здесь при обработке данных используются строгие спецификации так называемой закрытой модели. Слои и принципы взвешивания данных определены разработчиком теста и не меняются. Но можно оптимизировать массивы подаваемых данных, например. В случае открытой модели возможны и другие оптимизации, но результаты уже не получится сравнивать друг с другом.




















По сравнению с весенней версией 1.0, было добавлено не так много аппаратных конфигураций. Qualcomm предоставила существенно больше результатов для своих ускорителей Cloud AI 100, здесь они конкурируют с системами NVIDIA.
Аппаратные конфигурации изменились незначительно, но по программным оптимизациям было сделано очень много. Прирост составляет от единиц процентов до двух раз, причем поменялся только метод обработки данных на аппаратных системах.
Подписывайтесь на группы Hardwareluxx ВКонтакте и Facebook, а также на наш канал в Telegram (@hardwareluxxrussia).
Qualcomm атакует
В частности, в тесте Inference 1.1 очень высокие результаты показала система Qualcomm, которая вышла в лидеры во многих сценариях. Конечно, Qualcomm в данном сегменте ранее не была широко известна, но компания планирует с ускорителем Cloud AI 100 получить значительную долю на рынке дата-центров и периферийных вычислений.
Из некоторых примеров, где ускорители Cloud AI 100 хорошо проявили себя, можно отметить тест ResNet Offline. 16 Cloud AI 100 с энергопотреблением 75 Вт каждый оказались быстрее восьми A100 Tensor GPU на 500 Вт каждый. Эффективность - одна из сильных сторон систем Qualcomm. Особенно хорошо 75-Вт ускорители Cloud AI 100 подходят для периферийных серверов, причем они работают эффективнее NVIDIA A10 и A40 GPU.
Еще один важный фактор периферийных систем - задержки. Но и здесь Qualcomm показывает себя хорошо, с низкими задержками и низким энергопотреблением на операцию инференса.
NVIDIA мыслит стратегически
Что касается NVIDIA, то здесь компания мыслит стратегически. И если даже Qualcomm сможет показать себя хорошо в некоторых областях, NVIDIA в перспективе все равно выйдет в лидеры по инференсу. В случае NVIDIA прирост есть почти во всех областях, причина тоже кроется в программной оптимизации из-за отсутствия нового "железа". К сильным сторонам NVIDIA можно отнести полностью разработанный программный стек. Все же сегодня на NVIDIA работают в два раза больше разработчиков софта, чем инженеров аппаратных компонентов.
NVIDIA считает ускоритель Qualcomm Cloud AI 100 больше как конкурента младшим решениям инференса A30. Там, где ограничений по энергопотреблению нет, либо требуется максимально возможная производительность инференса, A100 Tensor GPU должны остаться в лидерах. Как обычно, надо смотреть не на длину полосок в отдельных тестах, а на картину в целом.
В интерпретации результатов NVIDIA есть еще один интересный момент: постоянные сравнения между серверами x86 и ARM, причем NVIDIA подчеркивает, что серверы ARM будут играть все более важную роль в дата-центрах, и они уже не будут уступать серверам x86. Поскольку NVIDIA заинтересована в покупке ARM (хотя сделке еще предстоит получить одобрение множества регулирующих органов), подобные ссылки на процессоры ARM явно в интересах NVIDIA.
Фирменное приложение MLPerf Benchmark
Вероятно, на неделе MLPerf представит фирменное приложение, которое появится в App Store iOS и Google Play. Оно будет симулировать типичные приложения референса, в результате можно будет сравнить производительность различных мобильных устройств.
Мы смогли протестировать бета-версию MLPerf Benchmark и провели тесты на iPhone X, iPhone 12 и 2020 iPad.
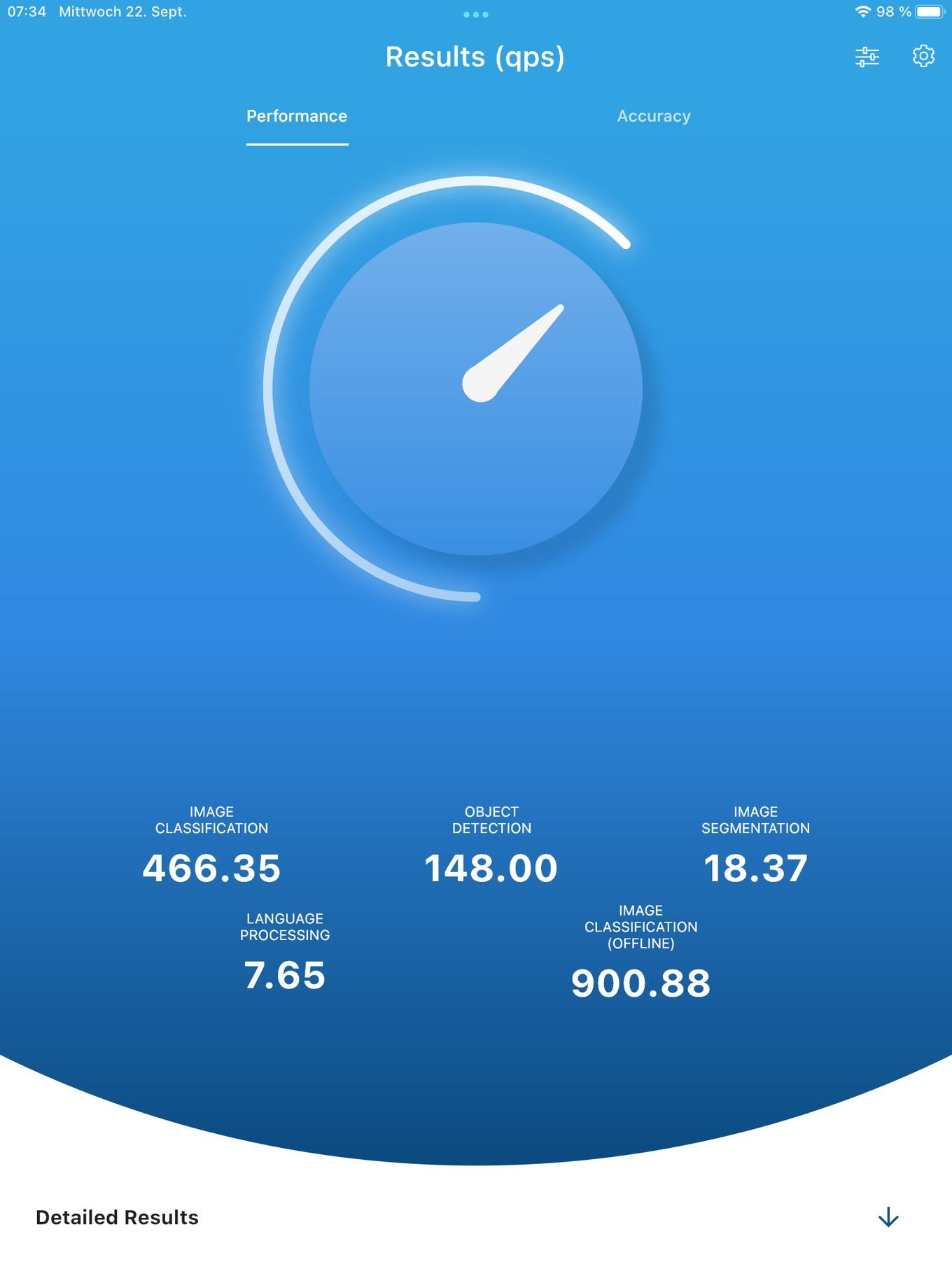
Производительность MLPerf Benchmark на iPad 2020
Производительность MLPerf Benchmark на iPhone X (слева) и на iPhone 12 (справа)
Три полученных результата весьма интересны, поскольку позволяют оценить прогресс за последние три-четыре года. Не только Apple, но и другие производители SoC планомерно усиливали ускорители ИИ. Их производительность заметна по результатам A12 в iPad и A14 Bionic в iPhone 12. В случае же iPhone X используется старая SoC A11, которая дает результаты существенно хуже.
Сложно оценить, насколько значимы будут подобные результаты. Конечно, тест позволяет сравнивать разные аппаратные конфигурации, но оценит ли пользователь, что распознавание изображения выполняется быстрее? В случае Apple iPhone анализ фотографий выполняется ночью, когда iPhone находится на зарядке. Потом, когда пользователь будет искать нужные снимки по фотогалерее, iPhone будет находить их только по тегам. Кроме того, обычно онлайновое распознавание изображений ограничивается скоростью подключения к Интернету, а не производительностью SoC.
Но MLPerf Benchmark все равно интересен для будущих обзоров смартфонов.