

Страница 2: GK110 в деталях

Мы уже много раз приводили снимок кристалла GK110. Но теперь все его компоненты задействованы. Основное пространство занимают кластеры SMX и кэши. По периферии располагаются интерфейс PCI Express и 64-битные интерфейсы памяти.

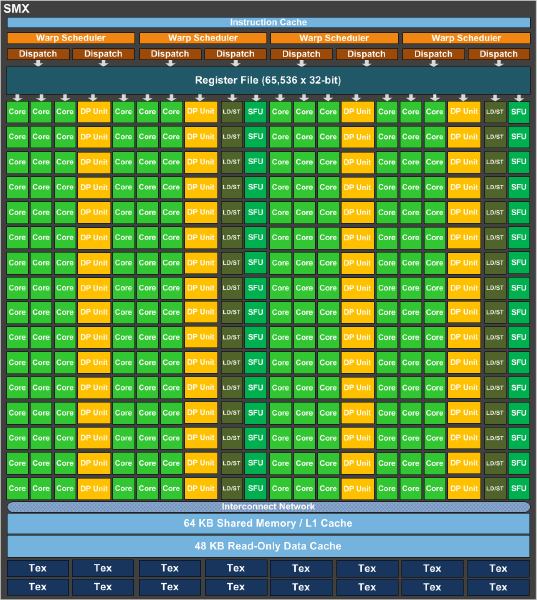
Эту иллюстрацию мы тоже неоднократно демонстрировали в обзорах GeForce GTX 780 и GeForce GTX Titan, хотя в данном виде GeForce GTX 780 Ti впервые стала использовать 15 кластеров SMX в пяти блоках GPC (Graphics Processor Cluster). Некоторую путаницу внесли разные версии GeForce GTX 780, поскольку на рынок вышли варианты с четырьмя и пятью кластерами GPC. В кластерах SMX содержится кэш, текстурные и вычислительные блоки, но растеризатор вынесен уже на уровень GPC (см. диаграмму). Каждый растеризатор обрабатывает восемь пикселей за такт. Поэтому в случае пяти GPC мы получаем обработку 40 пикселей за такт, в случае четырёх GPC - только 32 пикселей за такт. У видеокарты GeForce GTX 780 Ti подобной путаницы уже нет, так как все кластеры SMX и GPC используются.
Для видеокарт Tesla и Quadro на основе GK110 NVIDIA заявила о существенном приросте в производительности вычислений с двойной точностью и умеренном увеличении скорости обработки с одинарной точностью. По сравнению с GK104 в новой версии чипа были по-другому выставлены акценты вычислений FP32 и FP64. NVIDIA нацелила GK110, в первую очередь, на профессиональный рынок и высокопроизводительные вычисления HPC (High Performance Computing). Первая версия "Kepler" в виде GPU GK104 или GeForce GTX 680 позиционировалась именно как GPU для видеокарт GeForce, а для рендеринга ключевую роль играет производительность с одинарными вычислениями. Поэтому соотношение скорости работы с числами двойной точности к числам с одинарной точностью было уменьшено с 1/2 до 1/24. Наконец, графическая память у GK104 защищена ECC, но не кэш. Поэтому для профессионального рынка NVIDIA предлагает чип GK110, который теперь появился и в виде продуктов GeForce.
Для повышения производительности работы с дойной точностью NVIDIA установила 64 ядра с плавающей точкой на кластер SMX. В случае GK104 использовалось только восемь ядер на кластер. Вместе с увеличением количества кластеров SMX мы получили существенный прирост по производительности вычислений с числами дойной точности. NVIDIA осталась приверженной своей скалярной архитектуре "Superscalar Dispatch Method", которая впервые появилась в GF104, в результате чего вычисления более устойчивы к ошибкам. К ней относятся параллелизм на уровне потоков Thread Level Parallelism (TLP) и на уровне инструкций Instruction Level Parallelism (ILP), а также целочисленная линейная оптимизация.
По умолчанию ядра CUDA с двойной точностью на GeForce Titan работают всего на 1/8 частоты. В панели управления NVIDIA в 3D-настройках Titan есть пункт меню "CUDA - Double Precision". Если его активировать, то ядра CUDA с двойной точностью будут работать на более высокой тактовой частоте. Но у GeForce GTX 780 Ti эта опция исчезла.

Среди новых функций можно отметить "Power Balancing", которая ранее не встречалась. Её лучше понимать как способ синхронизации разных источников напряжения и разных PLL. Как известно, GPU и память питаются через слот PCI Express и два разъёма дополнительного питания PCI Express. Во время разгона может получиться так, что одна из данных линий станет ограничивающим фактором. Функция "Power Balancing" призвана устранить подобные "узкие места" и обеспечить лучший разгон.

Помимо технических данных NVIDIA подчёркивает эффективность GPU и энергопотребление. Если учесть тепловой пакет (TDP) видеокарты GeForce GTX 780 Ti на уровне 250 Вт, а Radeon R9 290X - 290 Вт, то с учётом площади кристалла 533 мм² или 455 мм² у NVIDIA мы получим преимущество в энергопотреблении на квадратный миллиметр. Целевая температура GPU Boost и PowerTune на уровне 83 или 95 °C играет уже не такую важную роль.
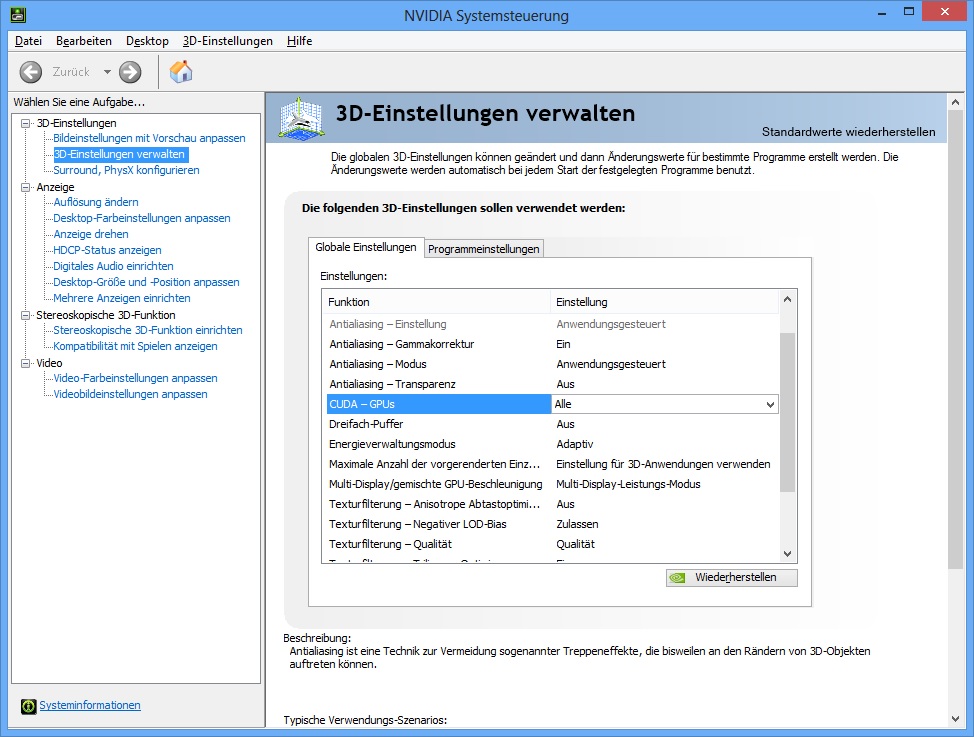
В отличие от GeForce GTX Titan, в панели управления NVIDIA Control Panel для GeForce GTX 780 Ti нет возможности включения более высокой тактовой частоты для ядер CUDA двойной точности. Так что они будут работать по-прежнему на 1/8 от частоты других ядер CUDA. Впрочем, данная опция была полезна только для тех пользователей, кто знал, что можно сделать с помощью вычислений двойной точности. Всё же она относится к профессиональному рынку.