

 Лейтмотивом конференции GPU Technology Conference стала технология глубокого обучения (Deep Learning). Но не менее интересны будущие технологии, которые будут использоваться в архитектурах GPU. В обновлённых планах NVIDIA говорится только об одной технологии - Mixed Precision. Но мы решили дополнить её известными данными о NVLink и 3D Memory. Помимо информации с пленарного доклада мы расскажем всё, что мы знаем о новых технологиях в одной статье. Не вся приведённая информация новая, но на протяжении конференции и за последние месяцы мы смогли узнать ряд интересных подробностей, которыми с удовольствием поделимся ниже.
Лейтмотивом конференции GPU Technology Conference стала технология глубокого обучения (Deep Learning). Но не менее интересны будущие технологии, которые будут использоваться в архитектурах GPU. В обновлённых планах NVIDIA говорится только об одной технологии - Mixed Precision. Но мы решили дополнить её известными данными о NVLink и 3D Memory. Помимо информации с пленарного доклада мы расскажем всё, что мы знаем о новых технологиях в одной статье. Не вся приведённая информация новая, но на протяжении конференции и за последние месяцы мы смогли узнать ряд интересных подробностей, которыми с удовольствием поделимся ниже.
Mixed Precision

В SoC Tegra X1 NVIDIA встроила GPU "Maxwell" с поддержкой "Double Speed FP16". Предыдущие архитектуры "Fermi" и "Kepler", как и "Maxwell" используют выделенные ядра CUDA FP32 и FP64. Есть они и в кластере "Maxwell" на SoC Tegra X1. Но в данном сегменте расчеты FP16 более важны. Поэтому NVIDIA изменила обработку команд FP16, чтобы они могли выигрывать от выделенных ядер FP32. Данные команды FP16 соединяются, чтобы их можно было выполнять на ядрах FP32. Команды FP16 могут объединяться, если они выполняют одинаковые вычисления. Например, можно объединить две команды сложения или две команды умножения. Операции FP16 под Android довольно важны в играх, а также при анализе фотографий и видео.
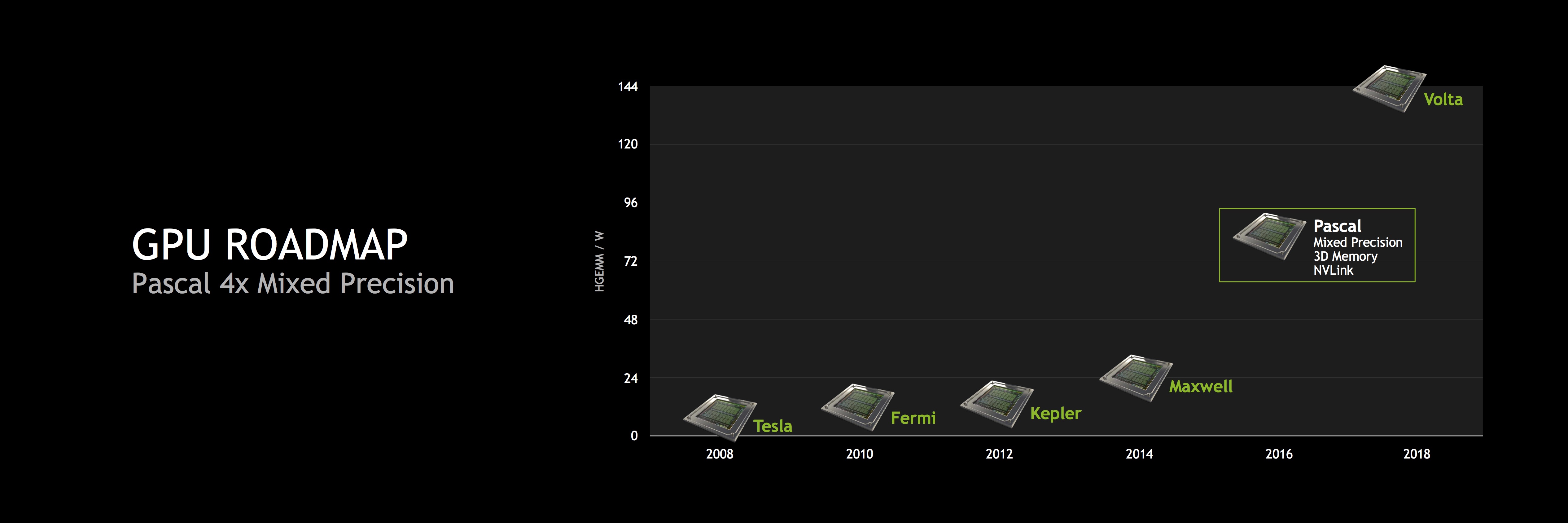
Какое отношение эта технология имеет к "Pascal"? В новой архитектуре "Pascal" будет использоваться технология Mixed Precision. Под этой технология как раз описанная выше скрывается функция потоковых процессоров, присутствующая в Tegra X1. Раньше технологии сначала появлялись в GPU GeForce, после чего переносились в SoC Tegra, но теперь мы получаем обратное направление – новинки в SoC Tegra появляются в грядущих архитектурах GPU. В Tegra X1 группируются операции FP16, которые важны в сфере обработки видео и фотографий. Android Display Composer тоже опирается на команды FP16, именно по этой причине в Tegra X1 столь большое внимание было уделено данным вычислениям. Но почему NVIDIA реализовала подобную технологию в "Pascal"? Скорее всего, NVIDIA планирует существенно увеличить производительность FP16. NVIDIA говорит от четырёхкратном увеличении по сравнению с "Maxwell". Нам ещё предстоит увидеть, насколько выиграют от данной технологии геймеры.
NVLInk
На самом деле на GPU Technology Conference мы не узнали ничего принципиально нового о NVLink. В профессиональном сегменте NVIDIA по-прежнему активно продвигает эту технологию, и IBM рассматривает поддержку NVLink в своих процессорах. NVIDIA предлагает программу лицензирования NVLink, и сегодня компания обсуждает её с несколькими партнёрами. Сама NVIDIA тоже активно участвует в развитии NVLink, в 2016 году NVLink будет использоваться в архитектуре "Pascal". Теперь позвольте поделиться известной информацией о NVLink.
Технология 3D Memory или Stacked Memory устраняет "узкое место" между GPU и видеопамятью. Интерфейс NVLink призван революционизировать соединение между GPU и CPU, а также между несколькими GPU. В данном отношении на первом месте находится пропускная способность, которая сегодня обеспечивается распространённым интерфейсом PCI Express. 16 линий PCI Express 3.0 обеспечивают пропускную способность 15,75 Гбайт/с или 128 GT/s. NVIDIA, например, с архитектурой "Maxwell" добавила технологию сжатия памяти, которая призвана удовлетворить растущие требования к пропускной способности памяти.
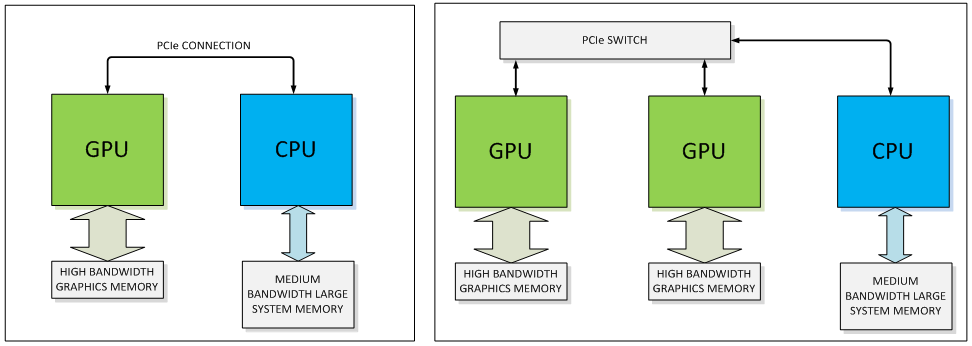
По информации NVIDIA, интерфейс NVLink в пять-двенадцать раз быстрее. Поэтому пропускная способность составляет 80-200 Гбайт/с. Но не следует забывать и конкуренте PCI Express 4.0, который должен появиться к тому времени. Он вновь удваивает пропускную способность PCI Express 3.0 до уровня 31,51 Гбайт/с или 256 GT/s.
NVIDIA использует для NVLink соединение точка-точка. Одно соединение NVLink опирается на восемь линий. У "Pascal" будет использоваться четыре соединения NVLink. По информации NVIDIA, количество соединений может изменяться в зависимости от целевого рынка - хотя это будет верно не столько для "Pascal", сколько для грядущих GPU. Соединения NVLink можно гибко комбинировать, если того требуют сценарии использования. Например, может использоваться простое соединение GPU-CPU, но также может быть задействована сеть соединений GPU-CPU и GPU-GPU.

Но кроме GPU поддерживать NVLink должен и CPU. Пока что только IBM объявила о поддержке интерфейса NVLink в процессорах PowerPC. По словам NVIDIA, компания обсуждает с производителями процессоров ARM идею добавить соответствующую поддержку к серверным решениям после представления "Pascal" на рынок. Конечно, NVIDIA разрабатывает собственную архитектуру CPU "Project Denver", которая выйдет на Tegra K1, также в серверном сегменте будет доступен альтернативный вариант с поддержкой NVLink. Здесь вновь следует подчеркнуть, что NVLink первое время будет распространяться только на профессиональном сегменте. Для настольных компьютеров будет вариант видеокарт "Pascal" без интерфейса NVLink, но с поддержкой PCI Express (к тому времени наверняка PCI Express 4.0). NVLink не сможет полностью заменить PCI Express даже в профессиональном окружении. По интерфейсу PCI Express будет передаваться информация управления и конфигурации, а через NVLink будут передаваться только данные для вычислений на GPU.
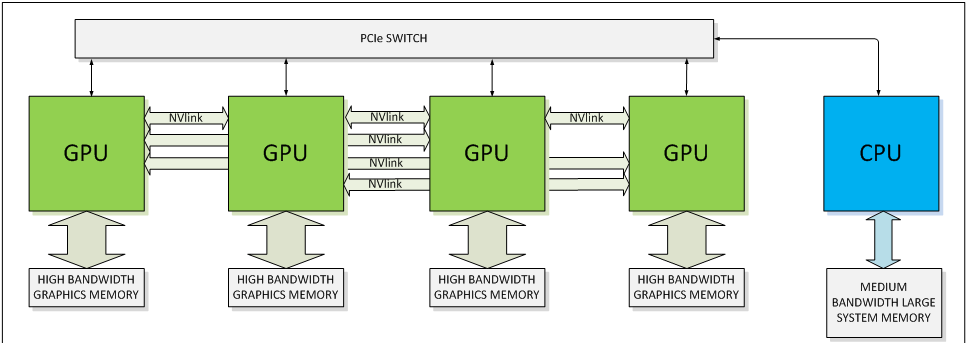
А теперь некоторая информация о NVLink применительно к GPU "Pascal". Пока что NVIDIA не планирует представлять подобный модуль "Pascal" для классических настольных ПК формата ATX. Будет интересно узнать, какие перемены нас ждут в будущем. Возможно, NVIDIA планирует заменить классический дизайн видеокарт, и модуль "Pascal" является одним из шагов в данном направлении.
3D Memory
NVLink в следующем году появится на архитектуре "Pascal", в лучшем случае, с видеокартами Tesla. И для геймеров в обозримом будущем по-прежнему будет актуален интерфейс PCI Express. Вероятно, самый большой шаг вперёд по производительности NVIDIA связывает с памятью NVIDIA. Неслучайно в конференции GPU Technology Conference 2015 участвовала SK Hynix, разработчик и поставщик памяти High Bandwidth Memory (HBM) для AMD и NVIDIA. Сотрудничество между AMD и SK Hynix позволяет надеяться на появление первых видеокарт с подобной памятью уже в этом году, но NVIDIA пока не комментирует концепцию 3D Memory.
Впрочем, на сегодняшний день понятно, что NVIDIA тоже активно работает с SK Hynix, и ниже мы приведём имеющуюся информацию о 3D Memory и поясним преимущества. NVIDIA использует HBM, как и AMD, по так называемому методу 2.5D. То есть слои памяти располагаются не на кристалле GPU, а вынесены рядом на подложку.

Скорость памяти определяется, по большей части, шириной интерфейса. AMD для тех же GPU "Hawaii" использовала очень широкую 512-битную шину, что заставило инженеров потрудиться над дизайном чипа, а также привело к его большой площади. Шина памяти тоже имеет важное значение. NVIDIA пока не делала попыток значительно расширить интерфейс памяти, довольствуясь 384 битами для "Kepler" и "Maxwell". Но NVIDIA добавила технологию сжатия памяти, которая должна несколько компенсировать невысокую пропускную способность памяти.
HBM в первом и втором поколениях будет опираться на четыре или восемь слоёв в чипах памяти. Они соединяются с помощью связей TSV (Through Silicon Vias). SK Hynix обеспечивает довольно хорошую гибкость конфигурации благодаря двум поколениям HBM и разному количеству слоев памяти. Так что у разработчиков GPU, таких как AMD и NVIDIA, имеется некоторая степень свободы конфигурации.
| Сравнение HBM | ||
|---|---|---|
| Поколение | HBM1 | HBM2 |
| Ёмкость на чип | 2 GB (4 слоя) 4 GB (8 слоев) |
4 GB (4 слоя) 8 GB (8 слоев) |
| Пропускная способность памяти | 128 Гбайт/с | 256 Гбайт/с |
| tRC | 48 нс | 48 нс |
| tCCD | 2 нс | 2 нс |
| VDD | 1,2 В | 1,2 В |
По скорости и ёмкости имеются возможности для манёвра. NVIDIA указала следующие характеристики памяти на своем пленарном докладе:

Высокая ёмкость обеспечивается четырьмя или восемью слоями HBM. Память GDDR5 с разными частотами сегодня имеет ёмкость 512 Мбайт на чип. HBM – первое поколение памяти с ёмкостью 2 или 4 Гбайт на чип. Во втором поколении High Bandwidth Memory от SK Hynix обеспечит ёмкость 4 или 8 Гбайт. Если посмотреть на изображение модуля NVIDIA "Pascal", то можно предположить увеличение объёма памяти до 8 Гбайт, что как раз составляет прирост в 2,7 раза, упомянутый на пленарном докладе. GeForce GTX Titan X (тест и обзор) с памятью 12 Гбайт x 2,7 даст около 32 Гбайт. Таким образом, NVIDIA для "Pascal" наверняка будет использовать 8-слойную память HBM второго поколения.

По пропускной способности NVIDIA ожидает прирост в три раза у "Pascal" по сравнению с "Maxwell". Четыре модуля памяти на плате "Pascal" в первом поколении дадут 512 Гбайт/с, у памяти HBM второго поколения мы получаем 1.024 Гбайт/с. Опять же, по сравнению с GPU GM200 "Maxwell" второго поколения с 384-битной шиной мы получаем утроение пропускной способности. Скорее всего, NVIDIA выберет 1.024 Гбайт/с у HBM второго поколения.
Итог таков: если судить по заявлениям об увеличении объёма и пропускной способности памяти "Pascal", NVIDIA выберет память High Bandwidth Memory второго поколения. Иначе заявленных значений по ёмкости и пропускной способности добиться не получится. Некоторые дополнительные детали о памяти HBM второго поколения вы можете найти в нашей новости, посвящённой SK Hynix на GTC 2015.
Перспективы
На пленарном докладе GTC 2015 Дженсен Хуанг упомянул различные аспекты повышения производительности "Pascal". Некоторые из них связаны с памятью, другие – с арифметическими операциями FP16 или вычислительной производительностью. Теоретически у "Maxwell" мы получили удвоение соотношения производительности на ватт. То же самое можно ожидать при переходе на "Pascal" с "Maxwell". NVIDIA указывает удвоение SGEMM на ватт. SGEMM обозначает производительность простых матричных операций.

NVIDIA давно выросла из разработчика игрового "железа". На последней конференции GPU Technology Conference это было более чем очевидно. Причём в этом году акценты были расставлены ещё более чётко. Конечно, видеокарты GeForce остаются "любим дитём" NVIDIA, но за прошедшие годы компания провела довольно серьёзную реструктуризацию. NVIDIA при разработке архитектуры GPU огромные усилия прикладывает к сфере вычислений на GPU. Конечно, видеокарты GeForce при этом вряд ли превратились в побочный продукт, так как вычисления на GPU и игры во многом пересекаются.
"Pascal" в ближайшие годы покажет, насколько далеко NVIDIA продвинулась по данному пути. Mixed Precision, NVLink и 3D Memory не нацелены на геймеров. По крайней мере, в первую очередь. NVLink для игр вряд ли полезна. А вот 3D Memory должна обеспечить прирост не только производительности вычислений, но и скорости в играх. Но ещё слишком рано делать какие-либо выводы по производительности. Сама NVIDIA указывает упомянутые числа как "грубую оценку". Будет ли GPU GM200 оставаться топовым решением до конца года, или NVIDIA приготовит нам GM210 – пока ещё нельзя точно сказать.