

 Пройдёт не один месяц, прежде чем на рынке появиться вычислительный ускоритель Tesla K20 на основе GK110, но конференция GTC 2012, вне всякого сомнения, значительно повысила ожидания от нового GPU NVIDIA. Сможет ли Nvidia им соответствовать на самом деле? Как покажет себя GK110 по сравнению с GK104 в видеокарте GeForce GTX 680? Какие изменения приготовила NVIDIA? В новостях уже не раз говорилась, что у "Большого Kepler" мы получим увеличение количества потоковых процессоров CUDA до 2880, а количества транзисторов - до 7,1 млрд. Но изменения архитектуры являются для многих "белым пятном". Мы решили обобщить всю информацию, полученную нами о GK110.
Пройдёт не один месяц, прежде чем на рынке появиться вычислительный ускоритель Tesla K20 на основе GK110, но конференция GTC 2012, вне всякого сомнения, значительно повысила ожидания от нового GPU NVIDIA. Сможет ли Nvidia им соответствовать на самом деле? Как покажет себя GK110 по сравнению с GK104 в видеокарте GeForce GTX 680? Какие изменения приготовила NVIDIA? В новостях уже не раз говорилась, что у "Большого Kepler" мы получим увеличение количества потоковых процессоров CUDA до 2880, а количества транзисторов - до 7,1 млрд. Но изменения архитектуры являются для многих "белым пятном". Мы решили обобщить всю информацию, полученную нами о GK110.

Процессор GK110 Nvidia нацеливает, в первую очередь, на профессиональный рынок и на использование в сфере HPC (High Performance Computing, высокопроизводительные вычисления). Tesla K10 базируется на двух GPU GK104, то есть на первом поколении "Kepler", поэтому он не удовлетворяет всем ожиданиям. Тем более что NVIDIA урезала GK104 во многих отношениях по сравнению с GF110/GF100. Например, шина памяти была уменьшена с 384 бит до 256 бит. То же самое касается кэша L2, который был снижен с 768 кбайт до 512 кбайт. Да и реструктуризация ядер CUDA в кластере SMX привела к тому, что соотношение скорости операций с двойной точностью и одинарной снизилось с 1/2 до 1/24. Наконец, у GK104 память защищена технологией ECC, но не кэш.

Tesla K10 на основе двух GPU GK104
Все эти изменения могут привести к тому, что вычислительные приложения на GK104 могут рассчитываться медленнее, чем на поколении "Fermi". С другой стороны, в GK104 было внесено несколько улучшений, от которых должны выигрывать приложения. Например, была существенно увеличена производительность работы с одинарной точностью, да и пропускная способность памяти увеличена благодаря подъёму тактовых частот. Так что пользователям предстоит оценить, стоит ли им оставаться на вычислительных картах "Fermi" или можно переходить на GK104.
Но давайте перейдём к GK110. Первым продуктом на основе оптимизированного GPU под вычисления станет Tesla K20. Карты можно ждать уже в октябре или ноябре этого года. Графический процессор NVIDIA GK110 должен устранить все недостатки, проявившиеся у GK104: процедуры определения ошибок ECC, увеличенная производительность с двойной точностью, более высокая пропускная способность памяти и дополнительные ядра CUDA.

У GK110 используются кластеры SMX, знакомые нам по GK104. Но они всё же несколько отличаются от "младшей" модели GK104. В максимальной конфигурации у GK110 используется 15 кластеров SMX, каждый из которых содержит 192 потоковых процессора CUDA. В общей сложности GK110 предоставляет 2880 потоковых процессора CUDA. 15 кластеров SMX подключены к 1,5 Мбайт кэша L2 и к подсистеме памяти через 384-битный интерфейс. В интервью, взятом сайтом Heise.de, два представителя команды разработчиков Kepler объяснили, почему они не реализовали 512-битный интерфейс памяти. С 7,1 млрд. транзисторов и площадью кристалла 600 мм² графический процессор GK110 (GK104: 294 мм²) уже стал самым большим чипом в мире (по количеству транзисторов), его нелегко производить по 28-нм техпроцессу и очень дорого. 512-битный интерфейс памяти потребует реализации ещё большего аппаратного обеспечения на стороне чипа - и Nvidia решила пойти на компромисс.
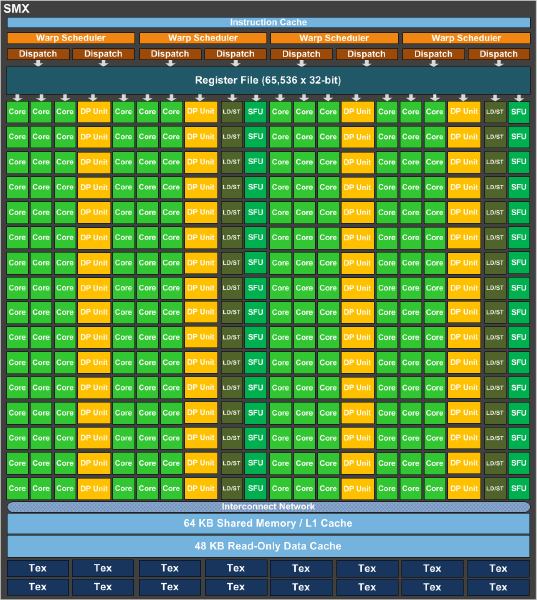
Для повышения производительности расчётов с двойной точностью NVIDIA на кластер SMX установила 64 ядра для работы с плавающей запятой. В GK104 используется только восемь таких ядер на кластер. Вместе с увеличением количества кластеров подобный шаг даёт значительный прирост по производительности с двойной точностью. Nvidia осталась приверженной своей скалярной архитектуре под названием "Superscalar Dispatch Method", которая впервые появилась в GF104, но с которой разработчикам следует быть внимательнее к ошибкам. Архитектура чуть более зависима от правильной реализации параллелизма на уровне потоков (TLP) и на уровне инструкций (ILP), включая целочисленную линейную оптимизацию.
Каждый кластер SMX оснащён 64 кбайт кэша L1 и 48 кбайт кэша данных на чтение. По сравнению с GK104 кэш L1 не изменился, но в кластерах GK110 мы получили 48 кбайт кэша данных на чтение. В каждом кластере SMX остаются 16 текстурных блоков, в результате чего GK110 даёт максимум 240 блоков TMU.

Tesla K20 на основе GK110
Производительность вычислений с двойной точностью была увеличена и через изменения в регистрах. Так, количество регистров на кластер SMX, а именно 65 536 регистров, осталось тем же самым, что и в GK104, но в GK110 доступны 255 регистров на поток, а в GK104 их было всего 63.
Мы уже упомянули выше более широкий интерфейс памяти, состоящий из шести 64-битных контроллеров, которые дают в сумме ширину 384 бита. В отличие от GK104 технология ECC защищает не только саму видеопамять, но также и кэши L1 и L2. Так как обнаружение ошибок всегда приводит к некоторым накладным вычислительным расходом, NVIDIA удалось снизить их благодаря внутренней оптимизации на 66 процентов.
| GF110 | GK104 | GK110 | |
| Техпроцесс | 40 нм | 28 нм | 28 нм |
| Число транзисторов | 3 млрд. | 3,54 млрд. | 7,1 млрд. |
| Площадь кристалла | 530 мм² | 294 мм² | предположительно 600 мм² |
| TDP | 225 Вт | 225 Вт | - |
| Тактовая частота GPU | 772 МГц | 1006 МГц | - |
| Тактовая частота памяти | 1000 МГц | 1502 МГц | - |
| Тип памяти | GDDR5 | GDDR5 | GDDR5 |
| Объём памяти | 1536 Мбайт | 2048 Мбайт | - |
| Ширина шины памяти | 384 бит | 256 бит | 384 бит |
| Пропускная способность памяти | 192 Гбайт/с | 192,2 Гбайт/с | - |
| Потоковые процессоры | 512 (1D) | 1536 (1D) | 2880 (1D) |
| Текстурные блоки | 64 | 128 | 240 |
| Кэш L1 | 64 кбайт | 64 кбайт | 64 кбайт |
| Кэш L2 | 768 кбайт | 512 кбайт | 1,5 Мбайт |
| ECC | Память и кэш | Только память | Память и кэш |
| FP64 | 1/2 FP32 | 1/24 FP32 | 1/3 FP32 |

Кристалл GK110
Hyper-Q и Dynamic Parallelism остаются двумя преимуществами GK110.
Hyper-Q:
В случае архитектуры "Fermi" GPU могли работать только с одной рабочей очередью команд и данных, но в случае "Kepler" ситуация уже отличается.

Одновременно с GPU "Kepler" могут работать до 32 физических ядер CPU. Конечно, данное ограничение не присутствует на программном уровне в интерфейсах DirectX 11, и несколько потоков могут выполняться одновременно, но передача данных и команд на GPU всё равно выполнялась последовательно. Благодаря поддержке Hyper-Q в будущем можно будет передавать данные параллельно.

Без поддержки Hyper-Q данные и команды передаются последовательно, загрузка GPU в данном случае не является оптимальной.

С помощью Hyper-Q данные и команды 32 физических ядер передаются одновременно. Это приводит не только к лучшему использованию GPU, но и к тому, что выполненные вычисления могут обрабатываться быстрее.
Кроме того, теперь множество GPU в системе могут напрямую связываться друг с другом. Технология "GPU Direct" как раз позволяет GPU "Kepler" связываться друг с другом даже по сети - обращение к CPU и памяти теперь уже не требуется.
Dynamic Parallelism:
Команды и данные, которые поставляются на GPU, могут быть взаимозависимыми (например, если расчеты зависят от результатов других вычислений), таким образом, части разных потоков могут блокироваться от выполнения на GPU некоторый промежуток времени. NVIDIA постаралась внести и улучшения обработки подобных ситуаций в интерфейс CUDA.

Технология Dynamic Parallelism на GPU может решать подобные проблемы зависимости. Впрочем, от программистов тоже требуются усилия, поскольку им следует учитывать неравномерности обработки GPU и запросы из памяти. Если созданные потоки превысят возможности доступной памяти GPU, то будет проводиться обращение через шину памяти PCI Express interface, что может вновь замедлить весь процесс.

GPU самостоятельно определяет, в каких пропорциях он будет допускать существование зависимостей. Всё это позволит Nvidia избежать сценариев, ограничивающих производительность.
Заключение:
После обсуждения всех изменений и оптимизаций архитектуры GK110, позвольте ответить на фундаментальный вопрос.
Сможет ли выиграть от всего этого геймер?
NVIDIA GK110 фокусируется на увеличении производительности при работе с числами FP двойной точности - но из-за огромного количества ядер CUDA производительность с числами FP одинарной точности тоже должна существенно возрасти. Всё это играет очень важную роль при обработке изображений, то есть повлияет и на рендеринг игр. В том же ключе можно рассматривать и увеличение количества текстурных блоков TMU Nvidia. Игровая производительность должна только увеличиться. Конечно, увеличение производительности чисел FP с двойной точностью и поддержка ECC будут уже не так интересны геймерам. Рост пропускной способности памяти не так важен (она уже весьма значительно, что мы видели по результатам тестов), но всё равно подобный шаг в GK110 можно только приветствовать.
Отметим, что у перехода на 384-битную шину памяти есть побочный эффект в виде возможности штатной установки 3 Гбайт видеопамяти. В высоких разрешениях и экстремальных настройках сглаживания 2 Гбайт памяти могут являться узким местом, о чём мы уже говорили в статье "Тест и обзор: Palit GeForce GTX 680 4 GB Jetstream".
Но не на все вопросы мы получили ответы. GK110 по-прежнему находится в состоянии разработки в лабораториях Nvidia, пусть даже первый опытный образец кристалла уже получен. В ближайшие месяцы мы должны узнать тактовые частоты нового GPU. Кроме того, всем интересно, сможет ли TSMC производить кристаллы GK110 для NVIDIA в нужном количестве. Хотя, надо сказать, за последние месяцы заводы TSMC немало продвинулись в плане улучшения качества производства.