

 На конференции SC12 Supercomputing в Солт-Лейк-Сити NVIDIA представила вычислительные карты для серверов и рабочих станций Tesla K20 и K20X на основе GPU GK110. Две версии, о которых мы поговорим ниже чуть подробнее, и объясняют путаницу, которая существовала в последние недели вокруг Tesla K20. Изначально поставщик стоечных серверов на GPU сообщил, что карты NVIDIA Tesla K20 будут использовать GK110 с 13 кластерами SMX, каждый со 192 ядрами CUDA, что дает 2496 ядер CUDA в общей сложности. Вскоре на открытии суперкомпьютера Titanium было указано на 2688 ядер CUDA, что указывает на 14 кластеров SMX. И существование двух версий карт объясняет подобный дуализм.
На конференции SC12 Supercomputing в Солт-Лейк-Сити NVIDIA представила вычислительные карты для серверов и рабочих станций Tesla K20 и K20X на основе GPU GK110. Две версии, о которых мы поговорим ниже чуть подробнее, и объясняют путаницу, которая существовала в последние недели вокруг Tesla K20. Изначально поставщик стоечных серверов на GPU сообщил, что карты NVIDIA Tesla K20 будут использовать GK110 с 13 кластерами SMX, каждый со 192 ядрами CUDA, что дает 2496 ядер CUDA в общей сложности. Вскоре на открытии суперкомпьютера Titanium было указано на 2688 ядер CUDA, что указывает на 14 кластеров SMX. И существование двух версий карт объясняет подобный дуализм.

Tesla K20X - новая high-end модель для вычислений на GPU, ускоритель ориентирован исключительно на серверы. Чуть менее мощная карта Tesla K20 нацелена и на серверы, и на рабочие станции.
| GF110 Tesla M2090 |
GK104 Tesla K10 |
GK110 Tesla K20 |
GK110 Tesla K20X |
|
| Техпроцесс | 40 нм | 28 нм | 28 нм | 28 нм |
| Число транзисторов | 3 млрд. | 2x 3,54 млрд. | 7,1 млрд. | 7,1 млрд. |
| Техпроцесс | 530 мм² | 294 мм² | предполож. 600 мм² | предполож. 600 мм² |
| TDP | 225 Вт | 225 Вт | 225 Вт | 235 Вт |
| Тактовая частота GPU | 1300 МГц | 2x 745 МГц | - МГц | - МГц |
| Тактовая частота памяти | 463 МГц | 625 МГц | - МГц | - МГц |
| Тип памяти | GDDR5-ECC | GDDR5-ECC | GDDR5-ECC | GDDR5-ECC |
| Объём памяти | 6144 Мбайт | 8192 Мбайт | 5120 Мбайт | 6144 Мбайт |
| Ширина шины памяти | 384 бит | 256 бит | 320 бит | 384 бит |
| Пропускная способность памяти | 177 Гбайт/с | 2x 160 Гбайт/с | 208 Гбайт/с | 250 Гбайт/с |
| Потоковые процессоры | 512 (1D) | 2x 1536 (1D) | 2496 (1D) | 2688 (1D) |
| Кэш L1 | 64 кбайт | 64 кбайт | 64 кбайт | 64 кбайт |
| Кэш L2 | 768 кбайт | 512 кбайт | 1,5 Мбайт | 1,5 Мбайт |
| ECC | Память и кэши | Только память | Память и кэши | Память и кэши |
| FP64 | 1/2 FP32 | 1/24 FP32 | 1/3 FP32 | 1/3 FP32 |
| Одиночная точность | 1,33 TFlops | 4,58 TFlops | 3,52 TFlops | 3,95 TFlops |
| Двойная точность | 0,66 TFlops | 0,19 TFlops | 1,17 TFlops | 1,31 TFlops |
Огромный прирост производительности в вычислениях с двойной точностью и скромный прирост производительности с одинарной точностью можно объяснить смещением акцента с FP32 на FP64. Графический процессор GK110 стал первым чипом NVIDIA, ориентированным полностью на профессиональный рынок и сферы HPC (High Performance Computing). Карта Tesla K10 базируется на двух GPU GK104, которые относятся к первому поколению "Kepler" и ориентированы, в том числе, и на GPU GeForce, а в рендеринге производительность с одинарной точность играет решающую роль. Рейтинг производительности с одинарной точностью по отношению к двойной точности был снижен с 1/2 до 1/24. Наконец, у GK104 технологией ECC защищается только оперативная память, но не кэши.

У GK110 был пересмотрен рейтинг между вычислениями с плавающей запятой с одинарной и двойной точностью, было увеличено количество ядер CUDA, увеличен до 1,5 Мбайт кэш L2, шина памяти расширена до 384 битов, защита от случайных ошибок обеспечивается технологией ECC. Почему же NVIDIA не выбрала 512-битный интерфейс памяти? Дело в том, что 7,1 млрд. транзисторов занимают на кристалле GK110 площадь около 600 мм² (GK104: 294 мм²), что позволяет назвать новый чип уже самым крупным в мире (по количеству транзисторов), по 28-нм технологии его непросто производить, да и очень дорого. 512-битная шина памяти потребовала бы ещё большей площади чипа аппаратно, так что NVIDIA пошла на компромисс.
Для получения более высокой производительности с двойной точностью, NVIDIA установила 64 ядра Floating Point на кластер SMX, у GK104 использовалось только восемь подобных ядер на кластер. Вместе с увеличением количества кластеров данный шаг привел к значительному приросту по производительности с двойной точностью. NVIDIA также опирается на свою скалярную архитектур "Superscalar Dispatch Method", которая появилась в GF104 и гарантирует более защищённые от ошибок вычисления. Эта архитектура опирается на параллелизм на уровне потоков Thread Level Parallelism (TLP) и параллелизм на уровне инструкций Instruction Level Parallelism (ILP).
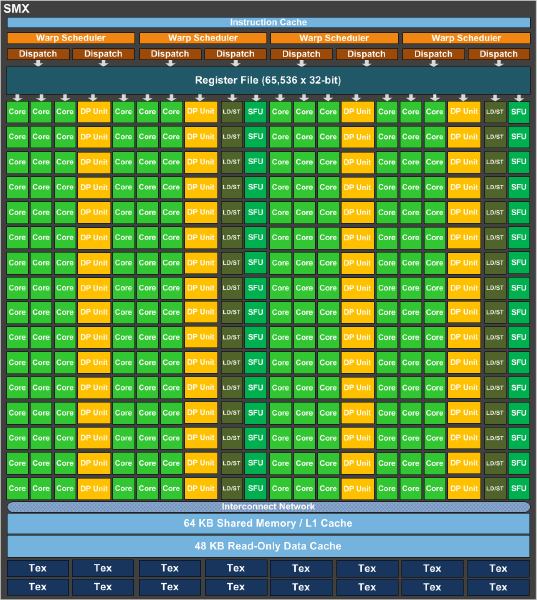
Каждый кластер SMX оснащен 64 кбайт кэша L1 и 48 кбайт кэша данных только для чтения. По сравнению с GK104, NVIDIA не стала затрагивать кэш L1, разве что в кластерах GK110 появился 48-кбайт кэш данных только для чтения. На кластер SMX по-прежнему используются 16 текстурных блоков, так что у GK110 мы получаем их, максимум, 240.
Производительность вычислений с двойной точностью была увеличения некоторыми изменениями в регистрах. Число регистров на кластеры SMX осталось прежним 65 536 по сравнению с GK104, но на поток GK110 обеспечивает доступ к 255 регистрам - в отличие от только 63 у GK104.
Как мы уже упоминали, интерфейс памяти стал шире, теперь он состоит из шести 64-битных блоков, которые вместе обеспечивают 384-битный интерфейс. В отличие от GK104, технология ECC защищает не только видеопамять, но и кэши L1 и L2. Поскольку определение ошибок подразумевает выполнение некоторых дополнительных вычислений, NVIDIA снизила вычислительные потери благодаря внутренней оптимизации до 66 процентов.
Hyper-Q и динамический параллелизм остались и в GK110.
Hyper-Q:
В случае архитектуры "Fermi" GPU могли работать только с одной рабочей очередью команд и данных, но в случае "Kepler" ситуация уже отличается.

Одновременно с GPU "Kepler" могут работать до 32 физических ядер CPU. Конечно, данное ограничение не присутствует на программном уровне в интерфейсах DirectX 11, и несколько потоков могут выполняться одновременно, но передача данных и команд на GPU всё равно выполнялась последовательно. Благодаря поддержке Hyper-Q в будущем можно будет передавать данные параллельно.

Без поддержки Hyper-Q данные и команды передаются последовательно, загрузка GPU в данном случае не является оптимальной.

С помощью Hyper-Q данные и команды 32 физических ядер передаются одновременно. Это приводит не только к лучшему использованию GPU, но и к тому, что выполненные вычисления могут обрабатываться быстрее.
Кроме того, теперь множество GPU в системе могут напрямую связываться друг с другом. Технология "GPU Direct" как раз позволяет GPU "Kepler" связываться друг с другом даже по сети - обращение к CPU и памяти теперь уже не требуется.
Dynamic Parallelism:
Команды и данные, которые поставляются на GPU, могут быть взаимозависимыми (например, если расчеты зависят от результатов других вычислений), таким образом, части разных потоков могут блокироваться от выполнения на GPU некоторый промежуток времени. NVIDIA постаралась внести и улучшения обработки подобных ситуаций в интерфейс CUDA.

Технология Dynamic Parallelism на GPU может решать подобные проблемы зависимости. Впрочем, от программистов тоже требуются усилия, поскольку им следует учитывать неравномерности обработки GPU и запросы из памяти. Если созданные потоки превысят возможности доступной памяти GPU, то будет проводиться обращение через шину памяти PCI Express, что может вновь замедлить весь процесс.

GPU самостоятельно определяет, в каких пропорциях он будет допускать существование зависимостей. Всё это позволит Nvidia избежать сценариев, ограничивающих производительность.
Эффективность энергопотребления:
В случае NVIDIA Tesla K20 и K20X мы получаем отличные результаты по эффективности энергопотребления. Если вы взглянете на список Green500, в котором компьютеры приведены по рейтингу эффективности энергопотребления, то на одном из первых мест находится BlueGene/Q с 16 ядрами на 1,6 ГГц и вычислительной производительностью около 2100 мегафлопов на ватт. В случае системы NVIDIA Tesla K20X мы получаем около 2250 мегафлопов на ватт. А цена такого решения ещё и в четыре раза ниже.
Использование в суперкомпьютере Titan:
Вычислительные ускорители Tesla K20X используются в суперкомпьютере Titan в Окриджской национальной лаборатории (штат Теннеси, США). Установленная система достигает пиковой производительности 27 петафлопов. Суперкомпьютер состоит из 18 688 GPU NVIDIA Tesla K20X и такого же количества 16-ядерных процессоров AMD (Opteron 6274). Как можно догадаться, Titan состоит из 18 688 узлов, которые объединены в 200 ячеек. На каждый узел доступно 32 Гбайт памяти, что даёт общую ёмкость оперативной памяти 710 терабайт.

Конкуренты:
Вчера утром AMD объявила новые вычислительные ускорители FirePro S10000 на основе двух GPU Tahiti Pro. Мы опубликовали новость и сравнение теоретической производительности, но в тот момент карты K20X и K20 ещё не были официально объявлены.
| Модель | AMD FirePro S10000 |
NVIDIA Tesla K20X |
NVIDIA Tesla K20 |
NVIDIA Tesla K10 |
NVIDIA Tesla M2090 |
| Одиночная точность | 5,91 TFlops | 3,95 TFlops | 3,52 TFlops | 4,58 TFLops | 1,33 TFlops |
| Двойная точность | 1,48 TFlops | 1,31 TFlops | 1,17 TFlops | 0,19 TFlops | 0,67 TFlops |
По чистой теоретической производительности вычислительный ускоритель AMD FirePro S10000 обгоняет конкурентов NVIDIA, будь то GK104 или GK110. Но следует учитывать, что AMD для FirePro S10000 указывает максимальное энергопотребление 335 Вт, в то время как NVIDIA K20X отличается энергопотреблением всего 235 Вт. Кроме того, NVIDIA нацелила GK104 и GK110 на другие сферы применения, что можно видеть по соотношениям производительности с одинарной и двойной точностью.