

Страница 2: Kaveri в деталях
Если "Richland" стал доработкой "Trinity", то "Kaveri" разрабатывался "с нуля". Архитектура "Steamroller" у двух новых процессорных модулей, если верить AMD, стала самым серьёзным шагом вперёд после представления "Bulldozer". Также и графические процессоры в Kaveri были переведены со старой архитектуры VLIW4 на более новую GCN, новые APU впервые поддержали долгожданную архитектуру HSA. Наконец, 28-нм техпроцесс тоже приятно дополняет общую картину.
Гетерогенная системная архитектура (HSA)
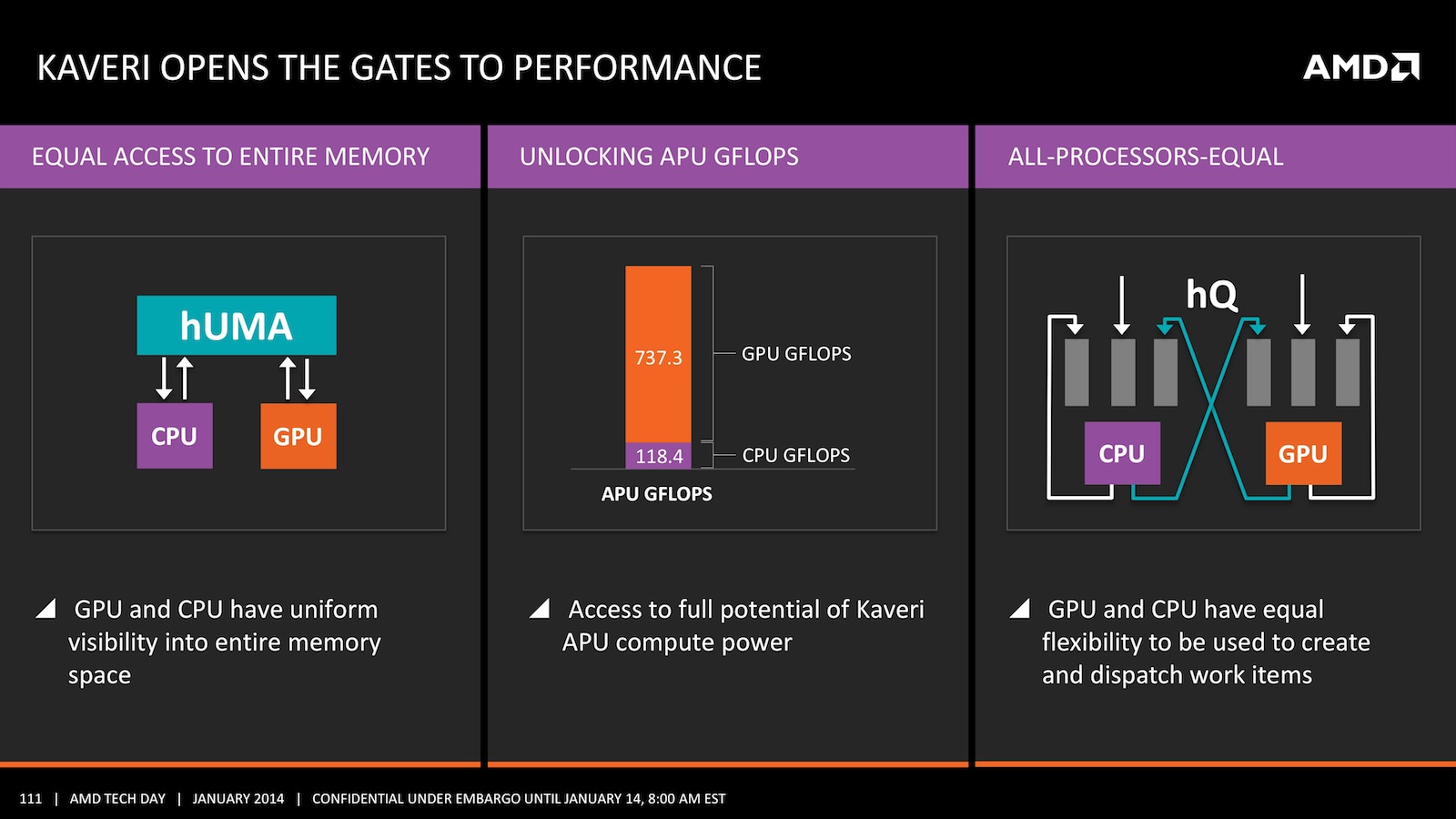
Самым важным улучшением "Kaveri" можно назвать гетерогенную системную архитектуру (HSA), когда графический и центральный процессоры работают более тесно друг с другом. В этом кроется одна из причин, почему AMD суммирует графические и процессорные ядра, говоря о вычислительных ядрах. Здесь следует ещё раз подчеркнуть две ключевые функции HSA: общую системную память (Shared System Memory) и гетерогенную очередь (Heterogeneous Queuing). Первая технология подразумевает общую память, к которой могут обращаться ядра CPU и GPU, напрямую обмениваясь данными друг с другом. Теперь не придётся копировать данные из одной памяти в другую с длительными задержками.
Технология общей памяти (её также называют hUMA) является обязательным требованием для гетерогенной очереди (hQ). До сих пор центральный процессор считался главным блоком, отвечающим за выполнение потока команд в программе. Теперь GPU и CPU могут равноправно распределять команды между собой, но, как и раньше, они лучше справляются со своими задачами. Ядра CPU хороши для выполнения последовательных задач, сильной же стороной GPU являются параллельные вычисления. AMD обещает более высокую эффективность вычислений благодаря грамотному распределению задач. Также для новых ядер "Steamroller" заявлен прирост производительности на такт (IPC) до 20%, но он несколько сглаживается снижением тактовой частоты.
Архитектура "Steamroller"
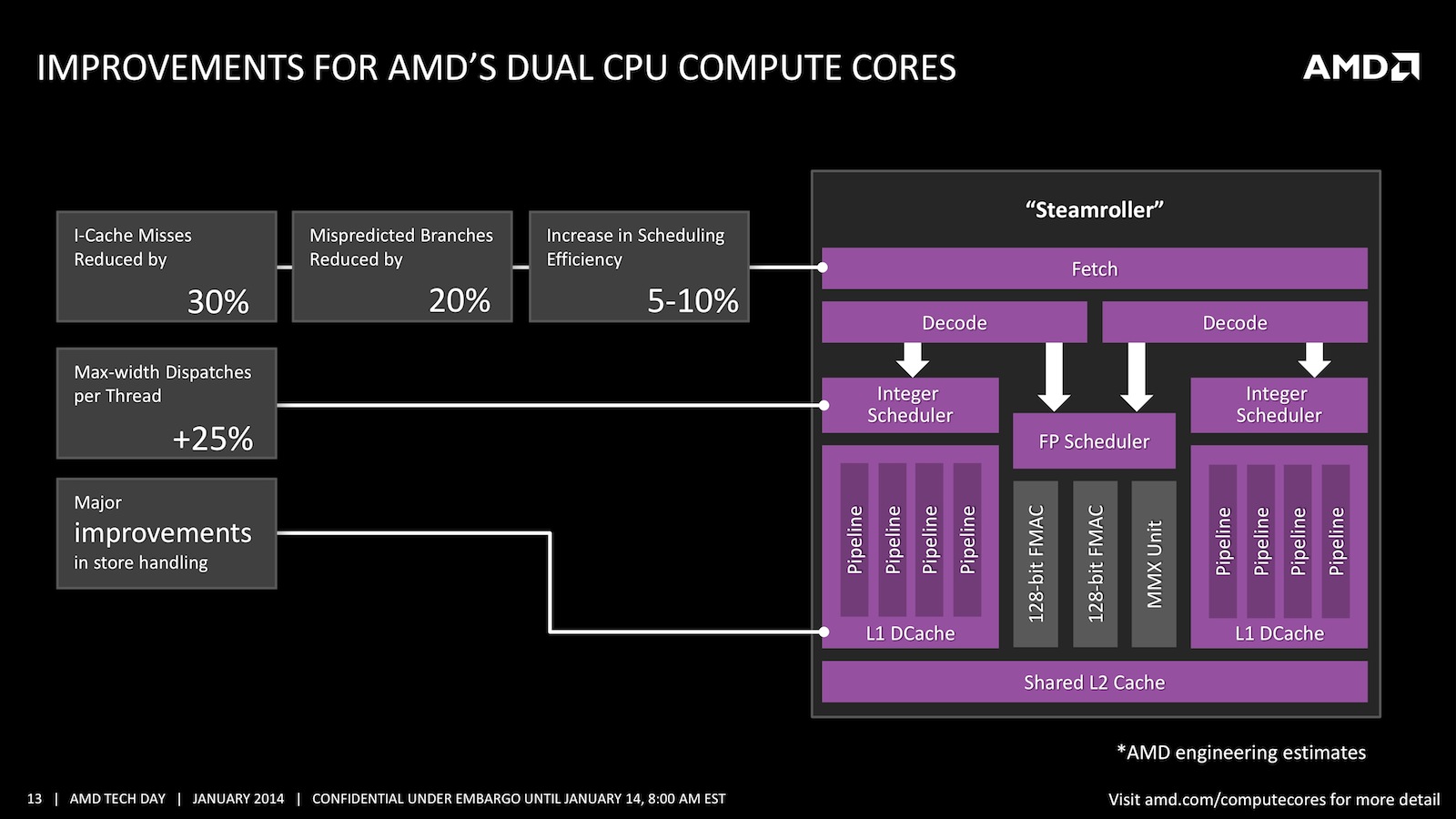
Новые ядра "Steamroller" должны исправить проблемы, существовавшие после появления архитектуры "Bulldozer". Но AMD по-прежнему твердо следует концепции "Bulldozer". В начале конвейера модуля располагается этап выборки команд (Fetch). Затем следует этап декодирования команд. Модуль состоит из двух целочисленных ядер и FPU, как и раньше, но AMD увеличила объём кэша инструкций на 50% до 96 кбайт - это должно уменьшить число промахов кэша на 30%. В блоке предсказания ветвлений буфер был увеличен до 10k записей, что уменьшает число неверных предсказаний на 20%. Буфер диспетчера выборки был увеличен с 40 до 48 записей, что тоже даёт на 10% большую эффективность выборки команд для параллельного выполнения.
Как видим, вместо общего целочисленного диспетчера AMD разделила его на две части, сейчас каждый модуль использует собственный целочисленный диспетчер. В результате ширина диспетчеров была увеличена на 25%. Есть и другие улучшения, на которых мы не будем подробно останавливаться.
В результате однопоточная производительность "Kaveri" должна значительно увеличиться. В расчете на такт ядра "Kaveri" будут давать до 20% большую производительность по сравнению с предыдущим поколением, но AMD снизила тактовые частоты.
Переход на архитектуру GCN

Новая архитектура GPU увеличивает производительность графических вычислений на уровень до 50 процентов. Возможности архитектуры GCN мы уже видели по новым графическим процессором "Volcanic Islands" и Radeon HD 7000, где она сменила старую архитектуру VLIW4. В старой архитектуре последовательные команды в программе распределялись на несколько мелких инструкций, которые затем параллельно выполнялись. Параллельно могли выполняться инструкции определенного вида, что на практике приводило к появлению "узких мест" и пустых слотов из-за отсутствия нужных инструкций. В GCN подобных ситуаций не возникает, поскольку используется совершенно иной подход. Базовым вычислительным блоком является Compute Unit, который состоит из четырёх векторных процессоров или SIMD, каждый содержит 16 АЛУ. В случае A10-7850K мы получаем восемь таких блоков (8 CU x 4 SIMD x 16 ALU), в результате можно говорить о 512 АЛУ или потоковых процессорах. К каждому блоку CU подключаются четыре текстурных блока, что дает 32 TMU в общей сложности. Интерфейс памяти 128-битный.
В целом, графический блок A10-7850K соответствует AMD Radeon HD 7750, но с несколько сниженными тактовыми частотами. AMD для всех новых APU "Kaveri" указывает тактовую частоту GPU 720 МГц. Напомним, что в случае Radeon HD 7750 она составляет 800 МГц.

Также процессоры "Kaveri" содержат знакомые нам ЦСП AMD TrueAudio, поддержку низкоуровневого API "Mantle" и PCI Express 3.0. Контроллер памяти DDR3 работает на довольно высокой частоте 2133 МГц. Новые модели APU относятся к настольному классу с тепловым пакетом 45-95 Вт. Для ноутбуков будут также представлены мобильные варианты APU с тепловым пакетом всего 15 Вт. Также отметим доработанные блоки кодировщика видео (VCE) и декодера видео Unified Video Decoder (UVD).
Новые материнские платы
К сожалению, переход на новую архитектуру потребовал и новой раскладки контактов, поэтому AMD для "Kaveri" вновь перешла на новый сокет. Если процессоры "Richland" устанавливались в Socket FM2, то в случае "Kaveri" используется новый Socket FM2+. Однако новый сокет обратно совместим с процессорами APU семейств 6000 и 5000. Вместе с тем AMD представила новые чипсеты A88X и A78. Они, за исключением небольших изменений, идентичны предшественникам A85X и A75. Также AMD указывает, что старый A55 FCH тоже будет поддерживаться.
