

 NVIDIA сегодня вполне ожидаемо представила архитектуру Ampere во время виртуального пленарного доклада GPU Technology Conference. Все подробности пока не раскрыты, но ключевые спецификации новых продуктов были объявлены. После представления архитектуры Volta три года назад NVIDIA теперь объявляет ее преемника.
NVIDIA сегодня вполне ожидаемо представила архитектуру Ampere во время виртуального пленарного доклада GPU Technology Conference. Все подробности пока не раскрыты, но ключевые спецификации новых продуктов были объявлены. После представления архитектуры Volta три года назад NVIDIA теперь объявляет ее преемника.
Архитектура Ampere была разработана с учетом нескольких целей. Конечно, на первом месте стоит увеличение производительности. И в некоторых сферах NVIDIA заявляет о 20-кратном приросте. Во-вторых, вычисления GPGPU должны стать более гибкими. Если сравнить архитектуры Volta и Turing, то первая явно ориентирована на HPC и тренировку ИИ, а Turing - на игры и инференс ИИ. В архитектуре Ampere сочетаются оба направления, что позволяет сделать дата-центры более однородными (Elastic Datacenter).
















Архитектура Ampere является ключом в стратегии NVIDIA HPC. Также представлены и новые технологии в сфере инфраструктуры ускорителей GPGPU, такие как более быстрый интерконнект NVLink и более умные сетевые подключения. Подробности мы рассмотрим ниже.
GA100: 7 нм и 54 млрд. транзисторов на 826 мм²
Как утверждает NVIDIA, новые системы на Ampere GPU для дата-центров уже производятся, так что скоро мы узнаем о первых проектах. Кристаллы GPU выпускаются по 7-нм технологии. Что касается площади чипа, то у GA100 GPU она составляет 826 мм². Число транзисторов - 54 млрд. Для сравнения, у предшественника GPU V100 мы получали 21,1 млрд. транзисторов на площади 815 мм². Но чип производился по 12-нм техпроцессу. Полный процессор EPYC базируется на дизайне Rome с девятью кристаллами (8x CCD + 1x IOD) и содержит в сумме 39,54 млрд. транзисторов.

Так что GA100 GPU - действительно гигантский чип. Он производится TSMC по техпроцессу 7N. В результате мы получаем самый крупный и сложный 7-нм чип на сегодня. Если верить NVIDIA, дальнейшее увеличение площади чипа практически невозможно при сохранении прямоугольной формы.
Кроме крупного кристалла с десятками миллиардов транзисторов, отметим шесть чипов памяти HBM2, которые обеспечивают в сумме емкость 40 Гбайт для GA100 GPU. Кристаллы памяти изготовлены Samsung. Но емкость 40 Гбайт разделена между шестью кристаллами не поровну. Хотя NVIDIA и установила шесть чипов HBM2, используются только пять. 5x 8 Гбайт как раз и дают 40 Гбайт для GA100 GPU, ширина шины - 5.120 бит. NVIDIA впервые реализовала архитектуру GPU дата-центров подобным образом. Titan V тоже использовал только три чипа HBM2 из имеющихся четырех, однако он был нацелен на другой рынок. Поскольку NVIDIA использует только 108 из предположительно доступных 128 SM чипа GA100 GPU, данное соотношение соответствует интерфейсу памяти, ширина 5.120 бит как раз набирается пятью чипами.
Сравнение вычислительной производительности
Как указывает NVIDIA, GA100 GPU оснащен 108 SM, каждый с 64 потоковыми процессорами, что дает в сумме 6.912 потоковых процессора. На каждый SM мы по-прежнему получаем 32 вычислительных ядра FP64. Но NVIDIA уполовинила число ядер Tensor с восьми до четырех на SM. Зато NVIDIA существенно расширила функциональность ядер Tensor.
Ядра Tensor впервые были представлены с архитектурой Volta. В случае архитектуры Turing они использовались и для видеокарт GeForce RTX, где ядра обеспечивали расчет картинки DLSS 2.0. Как и ожидалось, NVIDIA расширила возможности третьего поколения ядер Tensor, кроме INT16 и FP16, которые ранее были пределом по точности вычислений, теперь поддерживаются FP32 и FP64. Так что ядра Tensor не только существенно повышают вычислительную производительность сферы ИИ, но и поддерживают вычисления на шейдерах в сегменте HPC, где требуется более высокая точность. NVIDIA говорит примерно о 20-кратном приросте вычислений ИИ FP32.
| Ampere | Volta | Turing | |
| GPU | GA100 | GV100 | TU102 |
| SMs | 108 | 80 | 72 |
| Ядра FP64 / SM | 32 | 32 | 2 |
| Ядра FP64 / GPU | 3.456 | 2.560 | 144 |
| Ядра FP32 / SM | 64 | ||
| Ядра FP32 / GPU | 6.912 | ||
| Ядра Tensor / SM | 4 | 8 | 8 |
| Ядра Tensor / GPU | 432 | 640 | 576 |
| Производительность FP64 | 9,7 TFLOPS | 8,2 TFLOPS | 510 GFLOPS |
| Производительность FP64 с ядрами Tensor | 19,5 TFLOPS | - | - |
| Производительность FP32 | 19,5 TFLOPS | 16,4 TFLOPS | 16,3 TFLOPS |
| Производительность TF32 | 156 / 312 TFLOPS | - | - |
| Производительность FP16 | 39 TFLOPS | 32,8 TFLOPS | 32,6 TFLOPS |
| Производительность FP16 с ядрами Tensor | 312 / 624 TFLOPS | - | - |
| Производительность BFLOAT16 | 312 / 624 TFLOPS | - | - |
| Производительность INT8 | 624 / 1.248 TOPS | 130 TOPS | 261 TOPS |
| Производительность INT4 | 1.248 / 2.496 TOPS | 260 TOPS | 522 TOPS |
| Память | 40 GB HBM2 5.120 бит 1.536 Гбайт/с | 32 GB HBM2 4.096 бит 1.134 Гбайт/с | 48 GB GDDR6 384 бит 672 Гбайт/с |
| TDP | 400 Вт | 450 Вт | 280 Вт |
Вместе с третьим поколением ядер Tensor, NVIDIA представила новый формат работы с плавающей запятой. А именно TF32 или Tensor Float 32, который обеспечивает диапазон значений FP32, но точность лишь FP16. Таким образом, NVIDIA сочетает преимущества FP32 и FP16, адаптируя их к потребностям в определенных сферах.
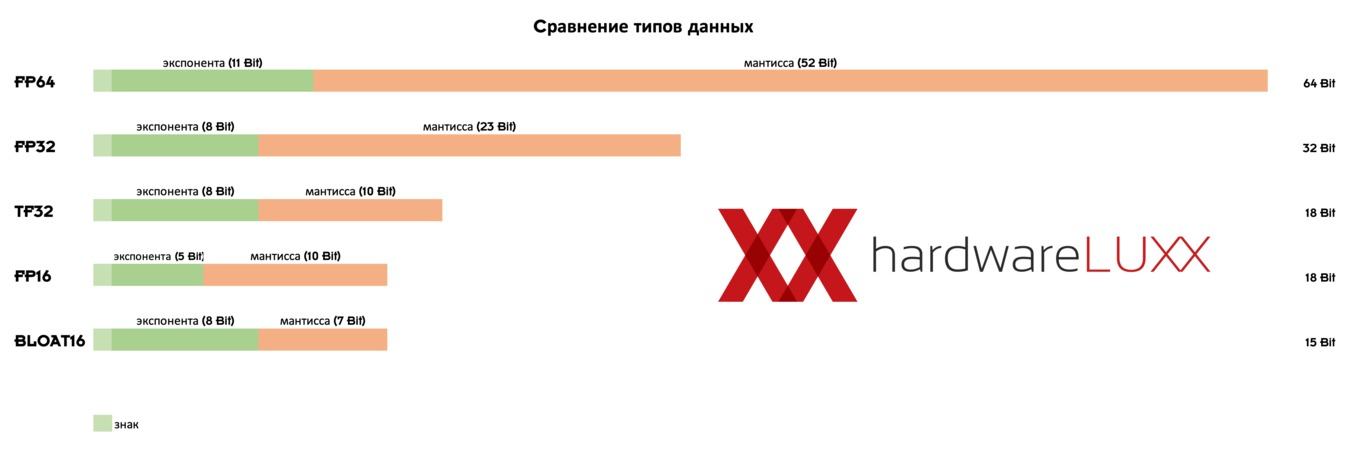
Что касается вычислительной производительности, NVIDIA представила новую технологию Sparsity/Sparse Matrix (разреженная матрица). Если матрица состоит из большого числа нулевых записей, то для ее хранения и вычислений можно использовать более эффективные способы. NVIDIA обеспечивает теоретическое удвоение вычислительной производительности при активной Structural Sparsity.
Наконец, можно привести сравнение с другими решениями HPC и ИИ: Radeon Instinct MI50 обеспечивает вычислительную производительность FP64 на уровне 6,6 TFLOPS, а вычислений INT8 - 53 TOPS.
MIG (Multi Instance GPU)
Новая технология архитектуры Ampere или GA100 GPU заключается в трансформации доступных ресурсов в семь независимых инстанций через Multi Instance GPU (MIG). GA100 GPU, в таком случае, представляет собой семь отдельных "младших" GPU. И семи виртуальным GPU будут присвоены собственные ресурсы по пропускной способности памяти, кэшам и т.д. В итоге GA100 GPU эффективно заменяет семь Tesla T4.
Если верить NVIDIA, технология MIG является отличным способом превращения обычно негибких GPU в Elastic Datacenter GPU, которые можно использовать для различных сценариев. Предыдущая технология Virtual GPU (vGPU) требовала многослойной программной обвязки (hypervisor и программа виртуализации) для такого же эффекта. Но MIG обеспечивает виртуализацию GPU намного ближе к аппаратному уровню, в итоге данная функция работает намного более эффективно.
Многое остается неизвестным
Остается неизвестным максимальное расширение, которое NVIDIA запланировала для GA100 GPU. Ходят слухи о наличии 128 SM. Для GA100 GPU NVIDIA активировала только 108 SM, так что довольно много ресурсов остается незадействованными. В случае GV100 GPU 80 из 84 доступных SM были активными, то есть из-за дефектов могли отбраковываться только 5%. Но 108 из 128 SM соответствует уровню дефектов 15% - намного больше, чем ожидалось.
Для архитектуры Turing NVIDIA впервые обеспечила одновременное выполнение вычислений INT32 и FP32, что весьма актуально для игровой производительности. Мы не знаем, имеются ли подобные блоки INT32 в архитектуре Ampere. То же самое касается и ядер RT для аппаратного ускорения трассировки лучей. Пока нет информации и об остальной части конвейера рендеринга. Вполне возможно, что у Ampere конвейера рендеринга вообще нет.
Так что пока нельзя вынести каких-либо заключений по поводу того, будет архитектура Ampere использоваться в грядущих игровых видеокартах GeForce или нет.
DGX A100: 8x Tesla A100 и 320 Гбайт памяти HBM2 в сумме








GA100 GPU будут использоваться, в основном, в серверах DGX. Серверы оснащаются восемью модулях SMX2. Вычислительная производительность, соответственно, кратно возрастает:
- FP64: 156 TFLOPS
- TF32: 2,5 PFLOPS
- FP16: 5 PFLOPS
- INT8: 10 POPS
Но DGX A100 представляет собой не просто набор из восьми GA100 GPU в модулях SMX2 каждый. Восемь GPU соединяются интерконнектом NVLink третьего поколения. Данная задача решается через шесть коммутаторов NVSwitch. Каждый из NVSwitch обеспечивает пропускную способность GPU-GPU 600 Гбайт/с. Что в два раза превышает пропускную способность Tesla V100. 600 Гбайт/с на GPU реализовано через 12 каналов NVLink по 50 Гбайт/с каждый.
В случае DGX A100 NVIDIA шесть коммутаторов NVSwitch обеспечивают суммарную пропускную способность 4,8 Тбайт/с.
NVIDIA больше не будет использовать процессоры Intel в системах DGX A100. Теперь в DGX будут устанавливаться два процессора EPYC от AMD на 64-ядерном дизайне Rome. Процессоры дополняются 1 Тбайт ОЗУ и 15 Тбайт NVMe SSD с подключением PCI Express 4.0.
Скорее всего, решающим фактором в пользу использования процессоров EPYC стала возможность подключения через PCI Express 4.0. Кроме NVMe SSD, через данный интерфейс подключаются девять Mellanox ConnectX-6 Lx SmartNIC, которые обеспечивают Ethernet на 2x 25 Гбит/с. Но пока сложно сказать, планирует ли NVIDIA оснащать системы DGX и HGX процессорами EPYC в будущем.
На данный момент GA100 GPU доступны только в модулях SMX2. NVIDIA не планирует предлагать их в виде карт PCI Express в обозримом будущем. Одна из причин этого решения - NVIDIA потратила немало усилий на разработку платы с восемью модулями SMX2, поскольку у столь сложной материнской платы имеются свои требования. OEM и ODM будут покупать уже полностью оснащенную материнскую плату, а не карты по отдельности.
Сервер DGX A100 стоит $199.999 и уже доступен для приобретения.
HGX A100 и Mellanox ConnectX-6 Lx SmartNIC
Также в виде HGX A100 NVIDIA предложила платформу, которая может содержать до восьми модулей SMX2 и сетевые подключения для гиперскейлеров. Соответствующие системы будут предложены OEM и ODM. Подобные системы с четырьмя GA100 GPU могут оснащаться специальными модулями EGX A100, на которых мы как раз остановимся ниже.
Мы уже упомянули Mellanox ConnectX-6 Lx SmartNIC. Они обеспечивают скоростное подключение к локальной сети. NVIDIA сочетает сетевые чипы ConnectX-6 с GPU GA100 и называет данные модули EGX A100. Они обеспечивают более тесное взаимодействие между GPGPU и сетью. Модули EGX A100 получают подключение 2x 100 Гбит/с через Ethernet или InfiniBand, причем напрямую к GPU или памяти GPU.
В системах DGX-A100 тоже используются интегрированные контроллеры Mellanox ConnectX-6 Lx SmartNIC. NVIDIA для своих систем DGX-A100 устанавливает девять подобных контроллеров с подключением 2x 25 Гбит/с. Конечно, здесь важным фактором является наличие поддержки PCI Express 4.0.
Скоростные интерконнекты довольно актуальны для рынка дата-центров. Между тем большое число производителей работают над интерконнектом CXL. А для соединения узлов дата-центров планируется использовать открытый стандарт Gen-Z. NVIDIA завершила приобретение Mellanox, и модули EGX A100 являются первыми плодами сотрудничества.
При возможности, данные не следует передавать между точками A и B в полном объеме, их следует оптимизировать, сжать и уменьшить. И как раз за эту задачу и отвечают так называемые SmartNIC. NVIDIA намеревается интегрировать интерконнект и сетевые технологии более глубоко в свои GPGPU. В таком случае центральный процессор для управления на уровне данных технологий уже не требуется. В принципе, у тех же ускорителей тренировки сетей глубокого обучения Gaudi от Habana Labs присутствуют десять сетевых контроллеров на 100 Гбит/с. Для Habana Labs очень важны быстрые интерконнекты с минимальными задержками.
Так что от NVIDIA можно ждать соответствующих шагов в будущем. Сетевая инфраструктура - важный аспект, но программную обвязку тоже не стоит списывать со счетов. NVIDIA использует сетевой протокол RDMA over Converged Ethernet (RoCE). Он подразумевает передачу транспортных пакетов InfiniBand через Ethernet. Версия RoCE v2 получит различные улучшения, в том числе и по задержкам. Протокол RoCE v2 намного лучше подходит, например, для обращения к памяти по сети.
Первые DGX A100 уже отгружаются партнерам
NVIDIA уже поставляет первые серверы DGX-A100. Среди прочего, часть систем получит Аргоннская национальная лаборатория США, чтобы продолжать исследования по поиску лекарства/вакцины от COVID-19.
Конечно, в интересах NVIDIA продать как можно большее число серверов DGX-A100. Пять серверов DGX-A100 способны заменить 50 систем DGX-1 и около 600 дополнительных CPU в дата-центре ИИ. Вместо 25 стоек и энергопотребления 630 кВт, достаточно будет одной стойки и 28 кВт. Цена при этом снизилась с 11 до 1 млн. долларов США.
Здесь можно привести любимую фразу Дженсена Хуанга: "The more you buy, the more you save", то есть чем больше вы покупаете, тем больше экономите.
Но NVIDIA идет еще дальше: DGX A100 SuperPOD состоит из 140 серверов DGX A100 и обеспечивает вычислительную производительность 700 PFLOPS. NVIDIA добавила четыре таких кластера SuperPOD в свой суперкомпьютер SATURN V. И вместе с 1.800 старыми системами DGX производительность для вычислений ИИ увеличилась до 4,6 EFLOPS.
На виртуальном пленарном докладе GTC20 NVIDIA также показала различные промышленные применения систем, а также использование в сфере автономного вождения. Первые партнеры NVIDIA уже начали оснащать свои беспилотные автомобили платформой Drive AGX Xavier. В данном сегменте NVIDIA считает себя движущей силой - при поддержке серверов DGX-A100, конечно.
Drive AGX Orin все же будет базироваться на архитектуре Ampere в качестве GPU, первая информация о данной SoC была представлена в конце 2019.
Подписывайтесь на группы Hardwareluxx ВКонтакте и Facebook, а также на наш канал в Telegram (@hardwareluxxrussia).