 В начале апреля Intel представила третье поколение процессоров Xeon Scalable. Они опираются на дизайн Ice Lake SP, содержат до 40 ядер Sunny Cove и предлагают 64 линии PCI Express 4.0 вместе с быстрым 8-канальным интерфейсом памяти. Посмотрим, какую производительность покажут два топовых Xeon Platinum 8380 с 40 ядрами. Мы проведем сравнение с двумя предшествующими поколениями, которые предлагают по 28 ядер каждое.
В начале апреля Intel представила третье поколение процессоров Xeon Scalable. Они опираются на дизайн Ice Lake SP, содержат до 40 ядер Sunny Cove и предлагают 64 линии PCI Express 4.0 вместе с быстрым 8-канальным интерфейсом памяти. Посмотрим, какую производительность покажут два топовых Xeon Platinum 8380 с 40 ядрами. Мы проведем сравнение с двумя предшествующими поколениями, которые предлагают по 28 ядер каждое.
Также у нас готов сервер на EPYC из линейки 7003, чуть позднее мы представим сравнительные результаты конкурента AMD. Однако на это уйдет еще несколько дней, поскольку серверные тесты не совсем простые и требуют значительного времени.
Процессоры Ice Lake-SP хорошо демонстрируют проблемы, которые Intel получила с 10-нм техпроцессом, поскольку третье поколение Xeon Scalable появилось слишком поздно. Intel использовала данное поколение для изменения платформы и частичной переориентации, поскольку следующее поколение Sapphire Rapids выходит уже в конце 2021 года.
Подписывайтесь на группы Hardwareluxx ВКонтакте и Facebook, а также на наш канал в Telegram (@hardwareluxxrussia).
Ice Lake и Sunny Cove
Поколение Ice Lake должно было перевести на новую архитектуру все сегменты еще в 2017 году: ноутбуки, настольные ПК и серверы. Однако возникли проблемы с 10-нм техпроцессом, которые до сих пор полностью не преодолены. Все же здесь мы получаем негативные последствия подхода Integrated Device Manufacturer (IDM), когда производство и разработка чипов находятся под одной крышей. Но Intel все же видит в IDM больше положительных сторон, скоро компания перейдет на концепцию IDM 2.0. И к 2023/24 году Intel планирует вернуть себе роль технологического лидера. С 7-нм техпроцессом Intel собирается догнать других производителей полупроводников и преодолеть все существующие проблемы, которые вряд ли можно было бы проиллюстрировать лучше, чем процессорами Rocket Lake-S.
Но процессоры Ice Lake-H для ноутбуков с более чем четырьмя ядрами так и не вышли, как и модели Ice Lake-S для настольных ПК. Впрочем, с процессорами Xeon на Ice Lake Intel все же смогла выполнить план. Первые процессоры были отгружены клиентам еще в четвертом квартале 2020, произведено уже больше 200.000 чипов.

Для Intel архитектура Sunny Cove является первым существенным изменением базовой архитектуры CPU со времен Skylake в 2015 году. Шесть лет Intel продолжала улучшать архитектуру Skylake, несмотря на критику чиповый гигант все же смог существенно увеличить производительность архитектуры Skylake по сравнению с первым поколением CPU вплоть до итерации Comet Lake Refresh, которые оставались актуальными на настольном сегменте до недавнего выхода Rocket Lake-S. То же самое касается и улучшения 14-нм техпроцесса, поскольку архитектура Skylake хотя и вышла на 10-нм в гомеопатических дозах в виде Canon Lake, оптимизации между 14nm+, 14nm++ и 14nm+++ были весьма существенными. 14-нм процессоры Rocket Lake-S достигают частоты до 5,3 ГГц на одиночных ядрах и до 5,1 ГГц на всех восьми ядрах.
Однако теперь Sunny Cove знаменует переход на новую архитектуру, хотя и ей уже исполнилось два года. Intel внесла ряд изменений, специфичных для Xeon.

Intel для Sunny Cove использует 5-wide конвейер с внеочередным выполнением. В нем теперь имеются четыре станции Unified Reservation Stations (RS), что позволяет добиться лучшего параллелизма выполнения инструкций, чем в случае Skylake. Возможно, для предотвращения уязвимостей Spectre, Intel выделила четыре фиксированных порта для AGU (Address Generation Unit). К каждой паре AGU привязан блок чтения/записи (Load/Store). Для вычислений VEC и INT теперь присутствуют дополнительные вычислительные блоки на соответствующих портах. Все эти меры призваны увеличить производительность архитектуры.
Передняя часть конвейера получила большую емкость, Intel оптимизировала предсказания ветвлений. Вычислительные блоки Ice Lake были увеличены по двум измерениям: глубина и ширина конвейера, сейчас процессоры могут выполнять больше инструкций и поддерживают больше наборов инструкций.
Intel увеличила кэши и буферы по сравнению с Cascade Lake. Теперь они могут вмещать больше данных, количество блоков Load/Store было увеличено. В этом кроется одно из изменений Ice Lake-SP по сравнению с вышедшей ранее потребительской версией: кэш L2 увеличился с 512 кбайт до 1,25 Мбайт на ядро. В случае Cascade Lake емкость составляла 1 Мбайт на ядро.

Также Sunny Cove поддерживает новые наборы команд ISA. Среди них Vector-AES и SHA-NI, но также и AVX512. Первые два обеспечивают аппаратное ускорение шифрования и дешифровки. В результате мы должны получить ускорение многих алгоритмов криптографии, что как раз соответствует упомянутым Intel оптимизациям под специальные приложения.
Тесты серверов
Здесь сразу же хотелось бы обговорить важный аспект. Тесты серверов во многом отличаются от бенчмарков обычных компонентов. Проблема не только в том, как сделать сравнение наиболее эффективным и весомым, но и в более сложных требованиях.
Например, в сфере настольных ПК есть приложения (и игры), где имеет смысл отключать Hyper Threading (Intel) или Simultaneous Multithreading (AMD), но для большинства приложений два потока на одно ядро дают выигрыш, поскольку позволяют использовать ресурсы наиболее эффективно. В случае серверных приложений все иначе. Здесь многое зависит от того, поддерживает приложение HT/SMT или нет. И количество приложений, которые выигрывают от Hyper-Threading, не так велико по сравнению с настольным сегментом. Многие приложения запрограммированы так, чтобы выполнять один поток на ядро. Данная тенденция видна по серверным процессорам ARM. Здесь последние модели вообще лишились поддержки SMT. Кроме того, отключение HT или SMT предотвращает многие атаки по сторонним каналам.

Еще один уровень сложности добавляет Non-Uniform Memory Access или NUMA. Причем не только в многоскетных системах, где работает больше одного процессора. AMD столкнулась с проблемами первого поколения EPYC из-за дизайна, поскольку данные могли находиться в области оперативной памяти, которая подключена не напрямую к кристаллу, а доступна через NUMA. Такое обращение негативно сказывается на задержках и пропускной способности памяти.
Программное обеспечение должно знать о существовании нескольких кластеров NUMA и реагировать соответствующим образом, чтобы данные хранились там, где до них можно быстрее всего добраться. Если же программа не знает о кластерах NUMA, доступ к данным может осуществляться с увеличенными задержками и сниженной пропускной способностью. Данная тема добавляет еще один уровень сложности, если рассматривать не только доступ к оперативной памяти, но и данные в крупных кэшах. Здесь следует учитывать так называемые Sub NUMA Clusters (SNC). Intel предоставляет два SNC на сокет с современными процессорами Xeon. В случае системы 2S используются четыре кластера NUMA. Опять же, если программа знает о наличии кластеров NUMA, то данные можно хранить с высокой степенью оптимизации, что повышает производительность. Но если это не так, то SNC следует отключать. Что верно для большинства приложений.

Следует поговорить о взаимодействии программного и аппаратного обеспечения. Процессоры Intel, например, поддерживают AVX 512, то есть специальные наборы команд, которые приводят к существенному ускорению вычислений. Если приложение оптимизировано, то прямое сравнение между процессорами Xeon и EPYC затрудняется. Конечно, можно встать на позицию "я хочу сравнение 1:1 без поддержки AVX-512", либо все же дать возможность железу проявить себя в полную силу.
То же самое касается настроек компилятора для тестовых приложений. AMD предлагает оптимизированные настройки, как и Intel. Поэтому сравнивать 1:1 не всегда просто. Впрочем, следует помнить: аппаратное обеспечение всегда должно работать с максимально раскрытым потенциалом производительности. В конце концов, облачный провайдер или клиент заинтересованы в том, чтобы выжать максимум.
Все упомянутые выше аспекты играют важную роль в тестах, и их стоит обговаривать для каждого бенчмарка. Теперь позвольте перейти к нашей тестовой системе.














Intel предоставила нам эталонную тестовую систему Ice Lake под названием S2W3SIL4Q. Двухсокетная система содержит два Xeon Platinum 8380 на 40 ядер каждый. В качестве оперативной памяти установлены 16 32-Гбайт планок HMA84GR7CJR4N-XN. Опционально мы добавили 16x 128 Гбайт Optane Persistent Memory 200, с которой провели отдельный тест. Питание обеспечивается двумя блоками мощностью 2.100 Вт каждый. В систему установлен Intel SSD P5510 на 7,68 TB, SSD D3-S4610 на 960 GB и два Optane SSD P5800X на 800 GB каждый. Подключение к сети обеспечивается Intel E810-CQDA2 NIC.
Обзор Skylake-SP и Cascade Lake-SP
Мы уже провели несколько тестов серверных процессоров. В том числе сравнили два Xeon Platinum 8280 с предшественниками Xeon Platinum 8180. Переход со Skylake-SP на Cascade Lake-SP почти не давал прирост производительности за исключением тестов DL Boost. В случае Ice Lake-SP теперь появляется новая архитектура.
Процессоры Xeon Platinum 8180 и 8280 имеют по 28 ядер и могут обрабатывать 56 потоков. Поскольку они оба устанавливаются в сокет LGA3647 и работают на платформе Purley, мы тестировали их на идентичной материнской плате (мы использовали Supermicro X11DAi-N) с одинаковой конфигурацией памяти. Но Xeon Platinum 8180 работали с памятью на 2.666 МГц, а Xeon Platinum 8280 на 2.933 МГц. Все подробности конфигураций можно посмотреть здесь.

Разница у нас была не только по платформе, но и по охлаждению. Мы тестировали процессоры LGA3647 в собранной самостоятельно системе. Два Ice Lake SP установлены в стоечный сервер высотой 2U. Впрочем, отличия по уровню шума и температуре важной роли в сегодняшнем сравнении не играют. Единственное, мы убедились, что обе платформы и три поколения Xeon не уходят в температурный троттлинг. Для процессоров LGA3647 мы использовали два мощных кулера Noctua NH-U12S DX-3647. Даже под полной нагрузкой процессоры не нагревались выше 60 °C на 2.000 об/мин. Так что они были вполне на уровне с процессорами Ice Lake в стойке.
Для тестов Xeon Platinum 8180 и 8280 верно все сказанное выше по поводу настроек Hyper-Threading, SNC и компиляторов.
Intel Xeon Platinum 8380
- Whiskey Lake Plattform
- Coyote Pass Mainboard
- Software Development Platform 2SW3SIL4Q
- 16x 32 GB SK Hynix HMA84GR7CJR4N-XN DDR4-3200
- Intel Optane SSD DC P5800X 800 GB (OS)
Intel Xeon Platinum 8280
- Supermicro X11DAi-N
- 12x 32 GB SK Hynix HMA84GR7CJR4N DDR4-2933
- 2x Noctua NH-U12S DX-3647
- Intel Optane SSD 905P 960 GB (OS)
Intel Xeon Platinum 8180
- Supermicro X11DAi-N
- 12x 32 GB SK Hynix HMA84GR7CJR4N DDR4-2666
- 2x Noctua NH-U12S DX-3647
- Intel Optane SSD 905P 960 GB (OS)
| Xeon 8380 | Xeon 8280 | Xeon 8180 | |
| Архитектура | Ice Lake-SP | Cascade Lake-SP | Skylake-SP |
| Техпроцесс | 10 нм | 14 нм | 14 нм |
| Базовая частота | 2,9 ГГц | 2,7 ГГц | 2,5 ГГц |
| Частота Boost | 3,4 ГГц | 4,0 ГГц | 3,8 ГГц |
| All Core Turbo | 3,0 ГГц | 3,3 ГГц | 3,2 ГГц |
| TDP | 270 Вт | 205 Вт | 205 Вт |
| Кэш L2 | 50 MB | 28 MB | 28 MB |
| Кэш L3 | 60 MB | 38,5 MB | 38,5 MB |
| Интерфейс памяти | 8x DDR4-3200 4 TB DDR4 + 4 TB PMem | 6x DDR4-2933 3 TB DDR4 + 3 TB PMem | 6x DDR4-2666 768 GB DDR4 |
| Интерфейс PCI Express | 64 x PCI-Express 4.0 | 48x PCI-Express 3.0 | 48x PCI-Express 3.0 |
| Подключение UPI | 3x 11,2 GT/s | 3x 10,4 GT/s | 3x 10,4 GT/s |
| Цена | 8.099 USD | 10.009 USD | 10.009 USD |

В качестве операционной системы мы использовали Ubuntu.
| HT | SNC2 | |
| Y-Cruncher | Нет | Нет |
| Blender | Да | Нет |
| Embree | Нет | Нет |
| NAMD | Да | Нет |
| LAMMPS | Да | Да |
| Monte Carlo Simmulation | Да | Нет |
| AV1 Encoding | Нет | Нет |
| HEVCEncoding | Нет | Нет |
| VP9 Encoding | Нет | Нет |
| LLVM Compiling | Да | Нет |
| Apache | Нет | Да |
| PHP | Нет | Нет |
| SQL Lite | Да | Да |
| HammerDB | Нет | Нет |
| Aerospike | Да | Нет |
| Stream | Нет | Нет |
| MLC | Нет | Нет |
Для большинства тестов мы использовали компилятор GCC 10.3. Для приложений на основе oneAPI мы выбрали компилятор Intel oneAPI DPC++/C++. В BIOS системы конфигурировались на максимальную производительность. Механизмы энергосбережения мы отключали. Linux Governor тоже был выставлен на максимальную производительность.
Новые процессоры Ice Lake SP содержат до 40 ядер Sunny Cove, инновации коснулись также интерфейса памяти и снижения задержек кэша L3 и памяти.
По сравнению с предыдущим поколением Xeon, Intel увеличила число каналов памяти с шести до восьми. На каждом канале могут использоваться два модуля. По частоте памяти Intel перешла с DDR4-2933 на DDR4-3200 - по крайней мере, для самых быстрых моделей Xeon. Для сравнения: AMD тоже поддерживает DDR4-3200 с процессорами EPYC, но только с одним модулем на канал. Увеличение пропускной способности памяти со снижением задержек - в этом кроется секрет нового контроллера памяти Intel.

Несколько процессоров Xeon связываются друг с другом в многосокетной системе через Ultra Path Interconnect (UPI). Intel обеспечила каждый CPU тремя каналами UPI, каждый на 11,2 GT/s. Ранее пропускная способность составляла 9,6 и 10,4 GT/s. Таким образом, Intel удалось немного ускорить скорость передачи данных в многосокетных системах. Еще одним важным фактором является поддержка PCI-Express 4.0 - через два года после того, как AMD перешла на PCI Express 4.0 со вторым поколением EPYC, обеспечив возможность более быстрого подключения дополнительных компонентов в системе. С 64 линиями PCI Express у процессоров Ice Lake Intel предлагает лишь половину того, что дает AMD. У двухсокетной системы число линий будет 128, поскольку Intel использует UPI для связи между сокетами. AMD предоставляет лишь 192 линий в режиме 2S, поскольку 64 линии PCIe выделены под связь двух сокетов.


Intel указывает чуть более высокие задержки кэша L1, поскольку для попадания требуется больше тактов, улучшений в кэше L2 по сравнению с Cascade Lake не произошло, поэтому у AMD имеется небольшое преимущество. Однако с процессорами EPYC следует внимательнее оценивать кэш L3, поскольку данные могут храниться как в локальном кэше L3 CCD, так и в других CCD. Локальная задержка L3 у AMD составляет 13,4 нс, у Intel - 21,7 нс. Однако если требуется передать данные с кэша другого CCD, то задержка 112 нс у AMD существенно выше. Здесь отлично видна разница между монолитным дизайном и чиплетами. Но следует отметить, что у AMD кэш L3 составляет до 256 Мбайт, а у Intel - всего 38,5 Мбайт.
Еще одна проблема с задержками кроется в доступе к кэшу L3 удаленного сокета в многосокетной системе. Здесь у Intel задержка достигает 118 нс (у Cascade Lake: 180 нс), что существенно меньше платформы AMD EPYC с задержкой 209 нс.
Intel лучше позиционируется и по задержкам памяти 85 и 139 нс вместо 96 и 191 нс. Кроме того, частота DDR4-3200 поддерживается для двух DIMM на канале памяти, как мы уже отмечали выше, а в случае процессоров AMD EPYC - только для одного модуля на канал.
Кэш и задержки памяти
Конечно, мы не стали слепо полагаться на результаты Intel и провели свои тесты.
Intel Memory Latency Checker
Задержки кэша
Наши тесты показывают, что задержки все же чуть выше из-за более масштабной mesh-сети. Что верно для всех операций доступа в кэши L1, L2 и L3 новых процессоров Ice Lake SP. Включение SNC2 снижает задержки L1 и L2, поскольку mesh-сеть разбивается на две меньших сети.
Но Intel смогла заметно улучшить задержки доступа в кэш L3 второго сокета, что может дать преимущества в некоторых приложениях.
Intel Memory Latency Checker
Задержки чтения DRAM
Intel Memory Latency Checker
Задержки чтения DRAM - удаленный сокет
Задержки доступа в память увеличились, пусть даже ненамного. Зато мы вновь наблюдаем улучшение задержек доступа к памяти второго процессора (так называемый удаленный доступ).
Пропускная способность памяти
Stream
Copy
Stream
Scale
Stream
Triad
Stream
Add
Увеличение пропускной способности памяти является следствием перехода с шести каналов памяти на восемь, но также и частота увеличилась с DDR4-2666 (Skylake) до DDR4-2933 (Cascade Lake) и теперь до DDR4-3200 (Ice Lake). Intel также оптимизировала подключение внутренних контроллеров памяти, что ускоряет доступ ядер к памяти.Увеличение пропускной способности памяти является следствием перехода с шести каналов памяти на восемь, но также и частота увеличилась с DDR4-2666 (Skylake) до DDR4-2933 (Cascade Lake) и теперь до DDR4-3200 (Ice Lake). Intel также оптимизировала подключение внутренних контроллеров памяти, что ускоряет доступ ядер к памяти.

Сначала позвольте рассмотреть классические приложения рендеринга. Blender и Embree в полной мере используют доступные ядра и потоки, именно по этой причине мы активировали Hyper-Threading, но режим SNC2 отключали.
Blender
bmw27
Blender
classroom
Blender
fishy_cat
Blender
koro
Blender
pvaillon_barcelona
Blender
victor
Два Xeon Platinum 8380 работают на 45-50% быстрее по сравнению с предшественниками Xeon Platinum 8280. Основную роль здесь играет увеличение до 40 ядер против 28 ранее.
Embree опирается на ядро трассировки лучей, разработанное Intel. Ядра Intel поддерживают наборы инструкций SSE, AVX, AVX2 и AVX-512. Также мы использовали ISPC (Intel SPMD Program Compiler), который автоматически адаптирует движок рендеринга под упомянутые наборы инструкций.

Тест Embree сначала компилировался нормально, после чего использовался Intel SPMD Program Compile на инфраструктуре LLVM.
Embree
Crown
Embree
Crown (ISPC)
Embree
Asian Dragon
Embree
Asian Dragon (ISPC)
По производительности мы наблюдаем похожие результаты, что и в тесте Blender выше. В тестах рендеринга решающий фактор - экономия времени. Финальный рендеринг действительно можно получить быстрее, и в случае 24 кадров в секунду ускорение на 45% можно назвать очень существенным.

Перейдем к приложениям из сферы высокопроизводительных вычислений High Performance Computing (HPC), таким как симуляция. LAMMPS (Large-scale Atomic/Molecular Massively Parallel Simulator) - свободный пакет для классической молекулярной динамики, написанный группой из Сандийских национальных лабораторий. В тесте Mocassin используется симуляция метода Монте-Карло для представления ионизированной туманности в космосе. NAMD - симуляция молекулярной динамики.
Здесь требуется как можно больше потоков и ядер, поэтому мы включили Hyper-Threading. Мы выключили SNC2 за исключением симуляции LAMMPS.
LAMMPS Molecular Dynamics Simulator
20.000 атомов
LAMMPS Molecular Dynamics Simulator
молекула родопсина
Monte Carlo Simulation
Туманность 2019-03-24
NAMD - Scalable Molecular Dynamics
Симуляция ATPase (327.506 атомов)
И в данных приложениях, где число ядер решающим образом сказывается на производительности, новые процессоры Ice Lake обгоняют своих предшественников. В случае симуляции молекулярной динамики выигрыш более заметный, поскольку вместо симуляции 25 нс в день теперь результат составляет 39 нс в день. В зависимости от сложности модели можно получить весьма существенную экономию времени.
Еще один типичный сценарий касается кодирования мультимедиа. Здесь часто применяются программные кодеры, которые работают на CPU. У программных кодеров есть преимущество в виде более широких возможностей адаптации и гибкости. Вместе с тем аппаратные кодеры дают преимущество по эффективности. По этой причине Google разрабатывает собственные ASIC, Intel тоже занимается разработкой своих серверных GPU.
Кодирование мультимедиа
AV1
Кодирование мультимедиа
HEVC
Кодирование мультимедиа
VP9
Для кодирования мультимедиа мы выбрали файл 8K и использовали кодеки AV1, H.265 и VP9, результат мы фиксировали в виде частоты кадров.
Многие web-серверы и базы данных выигрывают от числа ядер, также от производительности IPC отдельных ядер, размера кэша и высоких частот.
Web-сервер
Apache
Web-сервер
PHP
По этой причине прирост производительности в тесте Apache и PHP на двух Xeon Platinum 8380 составляет около 60%.
Производительность баз данных
HammerDB - MariaDB
Производительность баз данных
HammerDB - MariaDB
Производительность баз данных
SQL Lite
Что касается СУБД, то здесь добавляются такие факторы, как пропускная способность памяти и интерфейсы подключения накопителей (SSD), поскольку данные необходимо считывать и записывать. Также здесь как раз к месту оказывается память Optane DC Persistent Memory. Но для нее мы сделали отдельный тест.
7ZIP - распространенный алгоритм сжатия/распаковки данных. Конечно, есть и другие алгоритмы, которые показывают себя лучше или хуже по эффективности сжатия. Но 7ZIP позволяет сравнить производительность между довольно широким числом платформ.
Производительность сжатия - 7ZIP
Распаковка
Производительность сжатия - 7ZIP
Сжатие
По производительности сжатия и распаковки два Xeon Platinum 8380 не дают преимущества, которое можно было бы ожидать, исходя из числа ядер. Но прирост все равно составляет порядка 30%.
Поддержка инструкций AVX-512 является одним из главных аргументов в пользу Intel. Благодаря этому Intel может очень быстро выполнять оптимизированные приложения. Та же технология DL Boost, например, выполняется через AVX-512_VNNI, да и для своих тестов Intel использует приложения с поддержкой AVX-512. В случае Ice Lake-SP набор инструкций AVX-512 был расширен и далее. В частности, были добавлены инструкции криптографических алгоритмов.
Со следующим поколением Xeon под кодовым названием Sapphire Rapids Intel планирует добавить еще один набор инструкций Advanced Matrix Extensions (AMX). ARM работает над открытым набором инструкций SVE2 для ускорения векторных вычислений.
В тесте Y-Cruncher поддерживается набор инструкций AVX-512. Здесь будет интересно сравнение с процессорами AMD EPYC, которые не поддерживают AVX-512.
Y-Cruncher
1T (500M)
Y-Cruncher
nT (25.000M)
В однопоточном тесте мы рассчитывали число Пи с точностью 500 млн. знаков. Здесь расчет выполняется всего на одном ядре (1T). Поскольку Xeon Platinum 8280 может увеличивать частоту ядра Boost до 4 ГГц, а Xeon Platinum 8380 - всего до 3,4 ГГц из-за проблемного 10-нм техпроцесса. Однако новая микроархитектура все же компенсирует низкую частоту, поэтому Xeon Platinum 8380 все равно быстрее предшественников.
В случае теста nT нагружаются все потоки, поэтому с большим отрывом впереди идут новые 40-ядерные флагманы.

Если рассматривать сложные серверные сценарии, то без бенчмарков DL Boost не обойтись. Для выполнения тестов нам пришлось выполнить дополнительную работу, чтобы подготовить тестовое окружение. В частности, мы скачали базу Open Images Dataset V6 от Google, занимающую около 600 Гбайт пространства, на которой мы будем тестировать приложения глубокого обучения.
Для расчета подавления шумов мы использовали сцену Moana Island от Walt Disney Animation Studios и провели тест Open Image Denoise. Здесь объем исходных данных составил 50 Гбайт. Для тестов баз данных мы воспользовались массивом на несколько терабайт. Сегодня с подобными объемами можно работать без особых проблем, но мы еще раз видим, насколько более существенные требования предъявляют серверные сценарии.
Инференс изображений < 7 мс
Open Images Dataset V5 - INT8-Data
Инференс изображений
Open Images Dataset V5 - INT8-Data
Чтобы провести инференс сети глубокого обучения, нам пришлось создать Residual Neural Network (ResNet) с 50 слоями, по которым классифицируются изображения. Чем больше слоев, тем более точно классифицируются изображения для последующей обработки запросов.
Однако непосредственно сам тест базируется на инференсе, то есть запросе данных в сеть глубокого обучения. Сначала мы оценили производительность в кадрах в секунду для массива данных INT8. Два Xeon Platinum 8280 примерно на 40-50% обгоняют своих предшественников. Здесь важную роль тоже играет ускорение DL Boost. Два Xeon Platinum 8380 работают еще быстрее, что связано как с увеличением числа ядер, так и с дальнейшей оптимизацией DL Boost и приростом IPC.
Инференс изображений < 7 мс
Open Images Dataset V5 - FP32 через INT8
Инференс изображений
Open Images Dataset V5- FP32 через INT8
Во втором тесте мы оценивали производительность при работе с более крупным массивом данных FP32. Точности FP32 здесь не требуется, поэтому приложение конвертирует данные в INT8. У двух Xeon Platinum 8180 нет ускорения INT8, поэтому им приходится обрабатывать FP32, скорость получается существенно ниже преемников Xeon Platinum 8280. Два Xeon Platinum 8380 показывают прирост производительности благодаря большему числу ядер и улучшению архитектуры.

OSPRay и Open Image Denoise
Трассировка лучей
Для трассировки лучей сцены Moana Island в Walt Disney Animation Studios требуется "классическая" вычислительная производительность. То есть перед нами типичная вычислительная задача рендеринга. Сначала мы измеряли время, которое требуется для трассировки лучей.
Разрешение кадра составляло 2.048 x 858 пикселей, трассировка лучей выполнялась с 64 семплами на пиксель (SPP). Двум Xeon Platinum первого и второго поколений потребовалось для этого около четырех минут. Два Xeon Platinum 8380 выигрывают от 40 ядер, поэтому дают примерно на 50% более высокую производительность.
Для примера: если удвоить разрешение и увеличить SPP до 256, то на расчет кадра уходит уже несколько часов.
OSPRay и Open Image Denoise
Подавление шумов
Следующим шагом мы применили фильтр Open Image Denoiser, который убирает шумы, появившиеся из-за отсутствующих семплов. Чем меньше семплов рассчитывается на пиксель, тем больше получается шумов. Фильтр Open Image Denoiser убирает шумы и заменяет их информацией, полученной через сеть глубокого обучения.
Ускорение DL Boost двух последних поколений Xeon хорошо проявляет себя по устранению шумов, поскольку два Xeon Platinum 8280 справляются за 11,6 с, а два Xeon Platinum 8180 оказываются почти в десять раз медленнее. Два Xeon Platinum 8380 выполняют задачу примерно в два раза быстрее прямых предшественников.
OSPRay и Open Image Denoise
Трассировка лучей и подавление шумов
Преимущество по расчетам подавления шумов отражается и на общем времени, которое уходит на расчет кадра. В нашем случае мы подразумеваем кадр с низким разрешением и небольшим количеством семплов. Результат можно экстраполировать на настоящее кинопроизводство - расчеты будут занимать намного больше времени, и ускорение подавления шумов даст более ощутимую экономию.
В середине прошлого года Intel представила второе поколение оперативной памяти Optane. Optane Persistent Memory 200, которая стала последним звеном в пирамиде памяти Intel. В зависимости от важности данных и требований к доступу, они хранятся на разных слоях.
Если рассматривать подсистему памяти, то доступ к кэшу выполняется с задержками в нано и пикосекунды, в случае оперативной памяти задержки увеличиваются до уровня 100 нс. В современных условиях в оперативной памяти могут храниться сотни гигабайт или даже терабайты. Конечно, скоростные Optane DC SSD имеют емкость несколько терабайт, но время доступа сравнительно высокое - 10 мс. Затем в пирамиде находятся обычные SSD, 3D NAND SSD и HDD.
Конечно, данные можно хранить на RAM-диске, но память DRAM дорогая, и ее объем в серверах ограничен. Optane Persistent Memory закрывает брешь между DRAM и Optane DC SSD. Так что речь идет, по сути, о RAM-диске.
Максимум половину слотов DIMM процессора Xeon можно оснащать Optane DC Persistent Memory (один модуль DRAM и один Persistent Memory на канал). Память Persistent Memory в формате DIMM может устанавливаться планками 128, 256 и 512 Гбайт. Максимальный объем памяти, таким образом, составляет 8x 512 GB DDR4-3200 + 8x 512 GB Optane DC Persistent Memory, то есть 8 Тбайт на сокет. При установке памяти в слоты следует убедиться, что планки Optane Persistent Memory расположены ближе к контроллеру памяти, чем модули DRAM на том же канале. Что неоднократно упоминается в руководствах сервера и материнских плат.
Планки Optane Persistent Memory 200 Series Persistent Memory Modules (PMM) доступны в тех же емкостях 128, 256 и 512 GB. Энергопотребление модуля составляет от 12 до 15 Вт.

Самой важной чертой можно назвать увеличение пропускной способности памяти (+25%) по сравнению с первым поколением, поскольку Optane DIMM работают на той же частоте, что и основная память (DDR4-3200).
От настроек системы зависит, как именно будут использоваться Optane DC Persistent Memory. В режиме App Direct Mode приложениям обеспечивается прямой доступ к памяти. Intel для этой цели как раз разработала модель программирования. Все приложения с ее поддержкой могут работать с памятью Optane DC Persistent Memory в режиме App Direct Mode.
Второй режим Storage over App Direct переводит планки Optane DC Persistent Memory в своего рода SSD. Можно выбирать размер блоков и файловую систему, после чего работать с памятью как с обычным диском. Есть и смешанный режим Mixed Mode, в котором разные каналы памяти можно настраивать индивидуально.
Ранее для тестов мы использовали 16x 32-Гбайт планок Hynix HMA84GR7CJR4N-XN. К ним мы добавили 128-Гбайт модули Optane Persistent Memory 200 на каждый канал памяти и процессор, в результате 256 Гбайт оперативной памяти на сокет превратились в 1.280 Гбайт.
Производительность баз данных
Aerospike
Для тестов баз данных с PMem мы использовали Aerospike. В двухсокетном сервере СУБД запускается на одном процессоре, а на втором - клиент. Поэтому по своей природе тест не является двухсокетным. Optane Persistent Memory работала в режиме App Direct. Объем созданной базы данных составлял 1 Тбайт, она содержала около 10 млрд. записей по 64 байта каждая. Мы выбрали такой объем намеренно, чтобы полностью исчерпать доступную DDR4 RAM и гарантировать подкачку с SSD. В таком сценарии Optane Persistent Memory уже показывает свой потенциал. Мы измеряли пропускную способность при соотношении 70/30% чтения и записи к базе данных.
В случае Xeon Platinum 8380 данные и индекс хранятся в Optane Persistent Memory, что уже невозможно при использовании только 256 Гбайт DDR4. В последнем случае в оперативной памяти DRAM хранится только индекс, но данные - уже на Optane SSD DC P5510. Этот накопитель нельзя назвать медленным, однако он становится "узким местом".
Впрочем, Aerospike можно довольно гибко конфигурировать, чтобы данные всегда оставались на SSD, а индекс - на SSD, в DRAM или PMem. Конечно, максимум производительности мы получаем при хранении данных и индекса в оперативной памяти. Но здесь узким местом является доступный объем. Кроме того, следует учитывать возможность сбоя питания и аварийной перезагрузки, поэтому на SSD данные хранить безопаснее. Если данные и индекс были расположены в ОЗУ, то их придется создавать повторно, в случае же PMem и SSD данные останутся "живы".
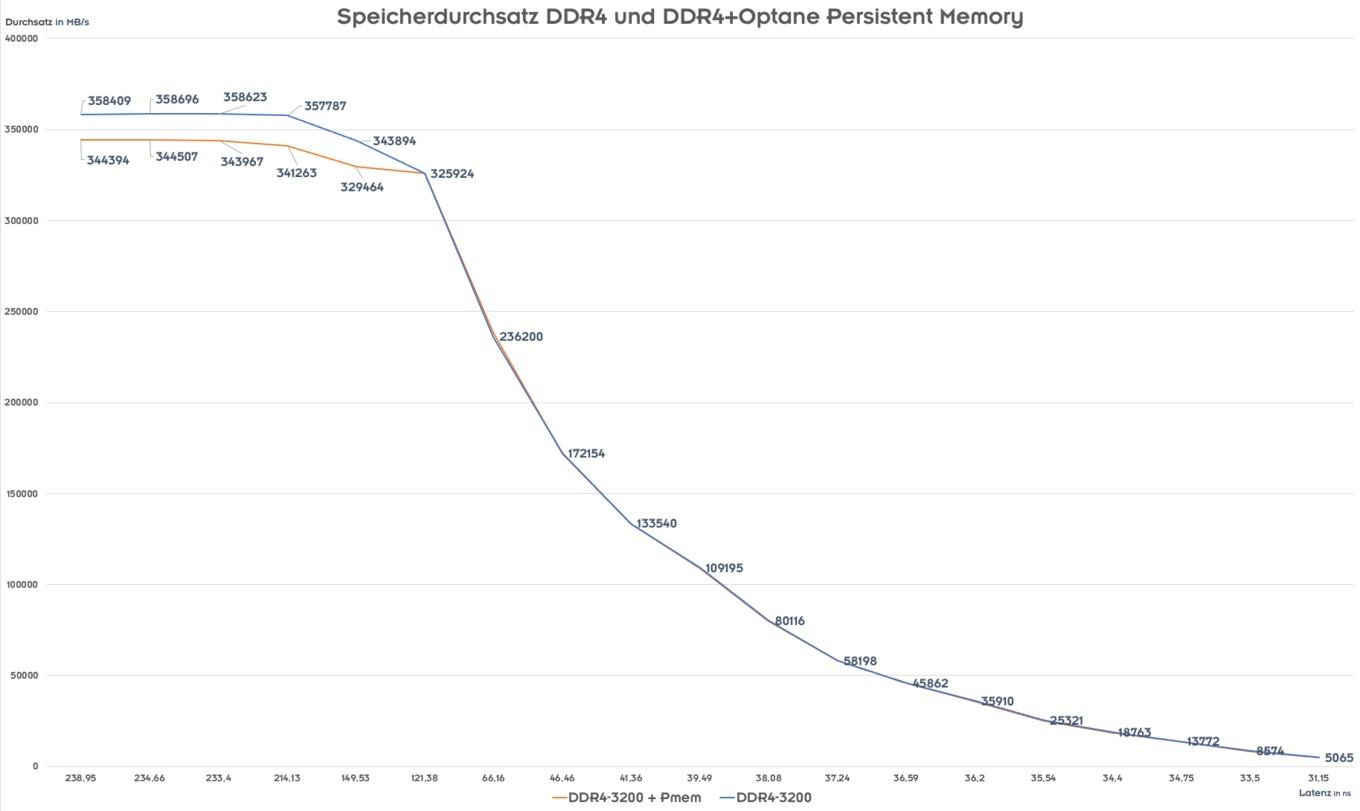
Хотя память Optane Persistent Memory работает на той же тактовой частоте, что и DDR4-3200, пропускная способность все же снижается. Впрочем, речь идет только о максимальной пропускной способности, что следует учитывать, если приложения к ней чувствительны.
Учитывая 10-нм техпроцесс и увеличение числа ядер, весьма интересен вопрос энергопотребления и эффективности. Впрочем, Intel увеличила TDP с 205 до 270 Вт, поэтому под полной нагрузкой энергопотребление вряд ли будет ниже. Скорее всего, мы получим увеличение. Поэтому нас не удивил результат: два Xeon Platinum 8380 показали Package Power 530 Вт под полной нагрузкой, в случае предшественников уровень был чуть выше 400 Вт. У серверных процессоров нет краткосрочного повышения Power Limit. Вопрос в том, обеспечивают ли два процессора Ice Lake прирост производительности, пропорциональный увеличению энергопотребления?
Одно можно сказать сразу: серверная платформа довольно экономичная в режиме бездействия. Вся система едва потребляла 150 Вт от розетки в режиме бездействия. Два Xeon Platinum 8380 потребляли примерно 25 Вт на сокет. Чипсет потреблял еще 20 Вт, вентиляторы не выключались, а они тоже имеют довольно высокое энергопотребление. Но стоечный сервер вряд ли будут покупать, чтобы он бездействовал. Поэтому интереснее оценить эффективность под нагрузкой.
Эффективность
Производительность на Вт
Мы рассчитали небольшой индекс эффективности, который учитывает энергопотребление и результаты некоторых тестов. В том числе рендеринга Embree, симуляции NAMD и Y-Cruncher.
Несмотря на высокое энергопотребление, два Xeon Platinum 8380 показали более высокую эффективность, то есть производительность в расчете на энергопотребление. Причина кроется и в более высокой производительности IPC, и в большем числе ядер. Мы рассчитали индекс эффективности с учетом разных приложений. Если рассмотреть их по отдельности, то в некоторых сценариях Ice Lake SP оказывается намного эффективнее предшественника. Коллеги Anandtech получили более высокую эффективность (на 37%) в целочисленных вычислениях и на 27% при вычислениях с плавающей запятой при нагрузке SPEC и нормализованном энергопотреблении на 205 Вт. Так что процессоры Ice Lake SP все же работают эффективнее предшественников.
При измерении энергопотребления следует учитывать несколько факторов. Хотя мы можем считывать Package Power в случае процессоров Intel, здесь необходимо добавить и чипсет, чтобы позднее сравнивать энергопотребление с платформами AMD и, возможно, ARM. Последние представляют собой SoC с интегрированным чипсетом, если так можно выразиться.
энергопотребление
Общее и Package Power под нагрузкой
Также сказываются и другие системные компоненты. Мы провели измерения с полной конфигурацией памяти DDR4 и под полной загрузкой ядер. Если добавить 16 DIMM Optane Persistent Memory, то мы получим еще 16 x 12 Вт = 192 Вт. То же самое касается скоростных SSD и т.д.
Полученные результаты позволяют сделать несколько выводов. Более высокий TDP процессоров Ice Lake SP увеличивает энергопотребление в расчете на сокет, то же самое касается и всей системы при прямом сравнении. Но если разделить 270 Вт на 40 ядер Xeon Platinum 8380, то мы получим всего 6,75 Вт/ядро, а не 7,32 Вт/ядро, как в случае предшественников Skylake (205 Вт на 28 ядер). Конечно, в подобных расчетах не учитывается на 33% более широкий интерфейс памяти, более крупные кэши и многое другое.
Ice Lake-SP и безопасность
Мы не рассматривали данный аспект в рамках тестов. Но с процессорами Ice Lake-SP Intel представила SGX (Software Guard Extensions) Secure Enclave - впервые в линейке Xeon. Ранее данная функция была доступна только у процессоров Xeon-E, где она использовалась для создания защищенных областей памяти. Например, AOK с помощью SGX планирует хранить электронные медицинские карты пациентов (ePA) с результатами анализов. У нас была возможность обсудить с Intel и разработчиками AOK ePA X-Tention.
Старшие процессоры Ice Lake SP могут работать с Secure Enclave емкостью до 512 Гбайт. Для системы 2S мы получаем 1 Тбайт защищенной памяти. Впрочем, так ли защищены эти данные? Все же за последние месяцы было раскрыто несколько уязвимостей. Против Load Value Injection или Plundervolt, а также CacheOut даже SGX не сможет ничего сделать, если защиту можно обойти.








Мы задали данный вопрос Intel и разработчикам. Как утверждают обе компании, SGX все равно обеспечивает существенно более высокий уровень защиты, поскольку некоторые атаки имеют больше теоретический характер, либо требуют физического доступа к серверу. SGX сужает число векторов атаки и является еще одним весьма серьезным препятствием на пути злоумышленника.
Если верить разработчикам ePA для AOK, Secure Enclave, который имеет емкость от 8 до 512 Гбайт, позволяет хранить значительные объемы данных. В нем можно хранить и обрабатывать рентгеновские снимки и результаты МРТ/КТ. Раньше Secure Enclave был ограничен максимумом 256 Мбайт, теперь до 1 Тбайт в сервере дает значительно больший объем. Использование SGX незначительно сказывается на производительности, единицы процентов, примерно на уровне Total Memory Encryption (TME).
ePA - лишь одна сфера применения Intel SGX. Если данные нужно не только считывать и записывать в зашифрованном виде, но и безопасно обрабатывать, Secure Enclave является еще одним шагом в направлении более эффективной защиты. Еще один пример - финансовый сектор, где можно обрабатывать массивы данных разных банков без риска раскрытия клиентской информации конкурентам.
Заключение
С процессорами Ice Lake-SP Intel внесла несколько инноваций. Здесь можно отметить новую микроархитектуру, 10-нм техпроцесс, более широкий и быстрый интерфейс памяти, наконец, долгожданную поддержку PCI-Express 4.0. Но третье поколение Xeon не только вышло слишком поздно, но и наглядно показывает проблемы, с которыми столкнулась Intel за последние годы.
43% увеличение числа ядер (40 против 28) и 32% увеличение производительности (270 против 205 Вт) кажется не слишком существенным, но Intel увеличила IPC, а также расширила и ускорила интерфейс памяти. Прирост IPC, в среднем, составляет около 18%, однако новые процессоры не достигают таких же высоких тактовых частот, как предшествующее поколение. Это верно и для All Core Turbo, и для максимальной частоты отдельных ядер. Но все не так просто, поскольку Intel может несколько компенсировать отставание по частотам различными оптимизациями Speed Select Technology вместе с Performance Profiles 2.0, в зависимости от приложения.
Но перейдем к оценке результатов тестов. По сравнению с двумя предыдущими поколениями Xeon Platinum 8380 является довольно сильной моделью при использовании всех ядер. Мы получили прирост производительности между 40 и 45%. Но это также означает, что Intel пока нечего выставить против 64-ядерной линейки AMD 7003 (Milan). То же самое касается конкурентов ARM с 64, 80 или даже 128 ядрами. Конечно, отставание благодаря новому поколению Intel стало меньше, но оно все равно имеется.
Если присмотреться, то картина становится интереснее. В тех областях, где Intel может предложить специальные решения, прирост производительности оказывается намного больше ожидаемого. Здесь можно упомянуть оптимизации доступа к памяти, от чего выигрывают базы данных и приложения DL Boost. То же самое касается использования памяти Optane Persistent Memory для работы с данными, которые не влезают в объем ОЗУ.
Важным аспектом являются 64 линий PCI Express по стандарту 4.0, которые повышают производительность ввода/вывода платформы Ice Lake. Intel ранее предлагала только 48x линий PCI Express 3.0, что кажется очень небольшим по сравнению с 128/192 линиями PCI Express 4.0 платформы AMD EPYC. AMD продолжает лидировать как по числу ядер, так и по линиям PCI Express.
Мы сможем показать полную картину, когда протестируем процессоры EPYC. Мы уже получили сервер и два варианта CPU для конфигурации 2S. Но с тремя поколениями Xeon мы создали основу для сравнения с процессорами EPYC в будущем, особенно в плане подбора тестов.
При изучении результатов тестов и новых технологий не стоит забывать о ценах. Intel пришлось скорректировать цены в ответ на действия конкурента. Даже топовые модели не продаются по ценам выше $10.000, в отличие от предыдущих поколений. Xeon Platinum 8380 стоят всего $8.099, то есть снижение составило 20%. Но Intel дает крупным клиентам и OEM весьма значительные скидки до 60%, так что оценить финальные цены сложно. По ценам на процессоры Ice Lake-SP видно, что Intel больше не может диктовать свою политику, игнорируя конкурента.
В итоге процессоры Ice Lake-SP можно назвать большим успехом Intel. Покупатели, придерживающиеся Intel, наверняка будут счастливы узнать об увеличении производительности и эффективности. Но Intel давно уже не одна на рынке, хотя компания лидирует по рыночной доле. С технологической точки зрения AMD и дизайны ARM обошли Intel, и только специальные оптимизации позволяют Intel лидировать в некоторых сценариях по производительности ядер/потоков.
Однако процессорам Ice Lake-SP отведен небольшой срок. Преемник Sapphire Rapids выходит ближе к концу года. Здесь можно рассчитывать на поддержку PCI Express 5.0 и DDR5, что вернет Intel к позиции технологического лидера по двум данным аспектам. Производство по новому техпроцессу (Enhanced) 10 nm SuperFin дополнит дальнейшие улучшения по микроархитектуре.
Подписывайтесь на группы Hardwareluxx ВКонтакте и Facebook, а также на наш канал в Telegram (@hardwareluxxrussia).